

You’d have to be living in a cave to not know that the practice of log analytics in corporate IT has grown dramatically in the last 10 years. This explosion in logging activities over the recent years is due to two factors, the maturing of log technology and the expanded application of logging to new information domains such as tracking user behavior, tracking page views, and tracking API interaction, to name a few such activities.
As logging technology matures, the price goes down. Getting and keeping data, the fundamental building blocks of log technology, are less costly due to the emergence of cloud technologies a part of the log analytics toolbox. (See Figure 1.)
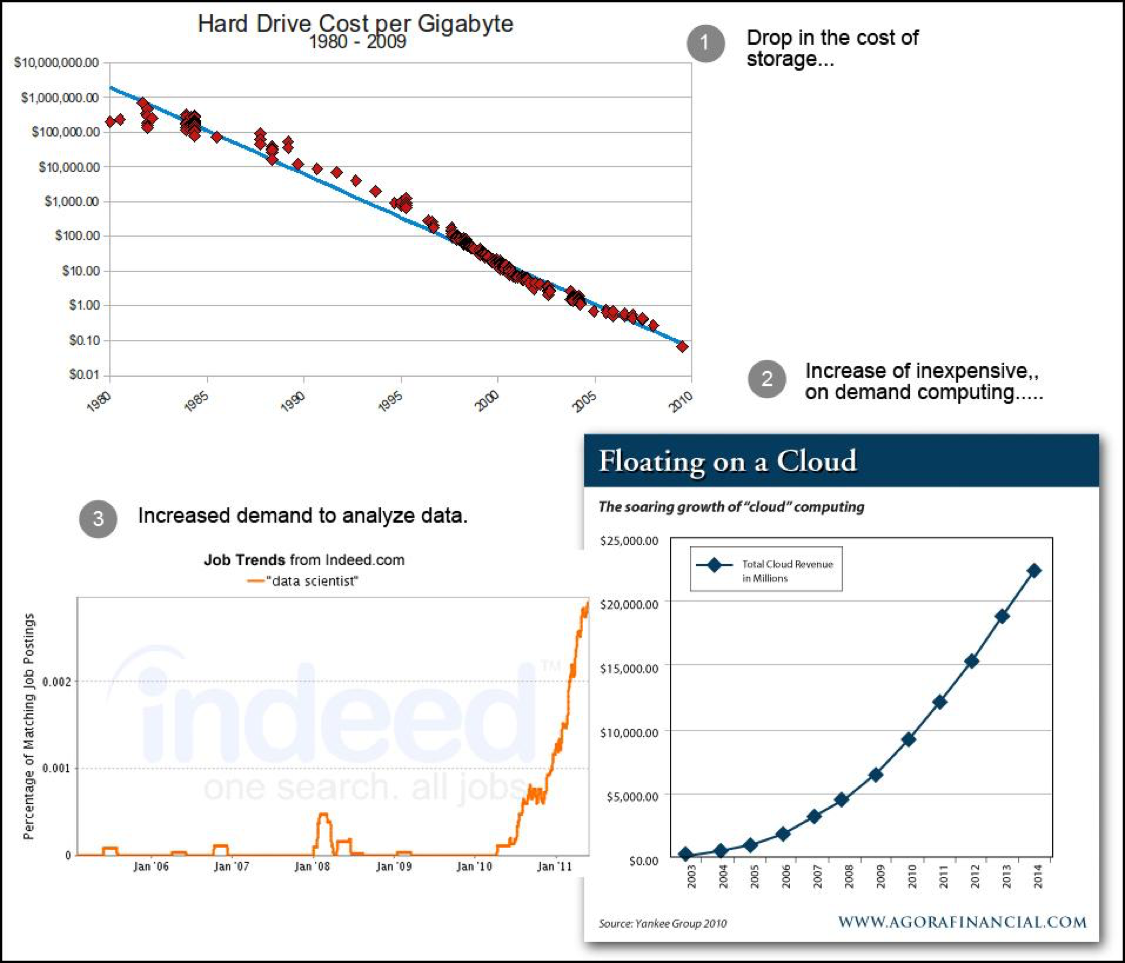 Figure 1: As costs drop (1 and 2) and demand increases (3), more tool providers enter the Log Analytics space.
Figure 1: As costs drop (1 and 2) and demand increases (3), more tool providers enter the Log Analytics space.Whereas in the past, there was not the variety and volume of data available to be gathered. Today there is more data than ever. And, that data shows up as logs. John Mark Walker, Director of Open Source Programs at EMC has an interesting take on the matter. To quote John Mark:
“Used to be, data centers could run on just a few vendors, hardware and software. Often on integrated stacks from a single vendor. [For example], mainframes, all the hardware and software came from a single vendor. That happens less often now. And in the early days of Unix, all the Unix vendors sold integrated stacks running their customized proprietary hardware and operating systems. Think Digital Equipment Corp.
Nowadays, ops find themselves running multiple flavors of operating systems from a host of vendors, all kinds of whitebox, off the shelf hardware, in addition to whatever integrated stacks they’re buying.
This leads to a set of problems: the complexity of the data center is immensely more than for previous generations, and there’s no one management platform to control it all.
In the old days, you bought your OpenView, installed the agents, and you were done. It was difficult to change its setup, but that’s OK because your data center setup didn’t change much anyway.
But now it’s a much different story – change is so rapid that something like the old management frameworks no longer work. So logs – they’re the only common denominator out there. It’s the only thing that you can reliably control and expect. So it’s what ops guys turn to when they want to do any kind of utilization analysis or root cause analysis when something goes wrong.”
But, as costs have dropped and more data is collected, things have changed. Companies that used to log nothing more than system and application events are now taking a broader approach because of the diversity of data. According to Ajit Zadgaonkar, Executive Director Infrastructure Engineering at Edmunds.com,
“The data we track on the engineering side is heterogeneous: multiple format, multiple data sources. some track time series, some track other stats and some pure log text and then there are many other standard logs like ELB logs, access logs etc..”
And, the very way one thinks about physical logging has changed. In the old days you had log files and that was it. You copied the files to a common location and executed commands from the command line, piping output to another file. Or you used a proprietary tool. That might have been adequate back then, but now there is just too much to consider.
David Trott, Director of Platform as Service at TicketMaster Inc. says the following:
“Logs are just a stream of events and many systems may have interest in processing them for different purposes.”
How poignant. In the past a company might have one or two sources of log streams to process. Today there might be hundreds, if not thousands of sources. And the structure of the data in those streams can vary, sometimes a lot. There is a lot of log data out there, in a variety of structures, that is interesting in a way that is particular to the systems and people consuming the data.
And this is where collection comes into play. To quote industry expert, John Martin, Team Lead with CHEF’s Solutions Engineering Group,
“Any log analytics solution should be able to aggregate logs from multiple sources, make searching from those sources easy, and be easily scalable as the number of sources increase.”
We can have our systems spewing log data all day long, but if we cannot collect and aggregate data easily and accurately, we’re at an impasse. It’s the old joke, “data, data all around me and not a bit to use!” Collection is critical.
As mentioned above, in the old days, collecting log data was simple, either you leveraged a single vendor or if you were supporting multiple sources, you worked with the file system and command line: think collecting files from an FTP site and running specific searches from the command line. Today, the techniques for collection are far more advanced. Modern companies use Agent and Agentless techniques.
When you use a log agent you are putting a piece of software, typically operating system specific, onto a machine of interest. That agent will collect the machine’s log data in real time and forward it to a target destination. That destination might be another machine or a software service.
An Agentless approach is, as the name implies, a technique for gathering log data in which no additional burden is placed on the host machine. Rather, you leverage the host machine’s capability for forward log data onto an identified target.
Yes. Logentries has Agents for Windows, Linux and Mac. You can configure your Linux/MAC OS to send log data onto targets supported by Logentries.
For the Agentless approach, Logentries can receive any data sent via syslog or a standard tcp connection. Logentries has documentation detailing how to configure all the major syslog services, including Rsyslog , Syslog-Ng , and Snare .
Today, no one person can do the figuring out required. Machine intelligence and data science come into play sooner than you’ll image.
Collection counts! And collection according to the need of the data consumer counts more.
Putting it together
Log data is a trove of treasure for any organization, always was, always will be. However, given the explosion in logging activity, old ways of working with log data will prove ineffective. Forward thinking companies put a good deal of thought and planning into determining a log analytics infrastructure that will meet the needs of current and future data consumers. Collecting and indexing log data in an efficient and flexible manner is necessary in order to have your organization realize a significant return on its investment. A well planned and executed log analytics practice will allow your organization to not only address today’s problem of the moment, but also to gather the intelligence required to predict future needs and hazards.
Create a free Logentries account in less than a minute at logentries.com.




