

By Benoit Gaudin and Mark Lacomber
Regular Expressions
When it comes to searching unstructured data, regular expressions are a very useful and powerful tool. The power provided by popular regular expression libraries does come with a significant performance cost in some cases though, both when compiling regular expressions into automata (state explosion problem when determinising automata) and when using these automata to match input. These constraints are usually acceptable for individuals needing to extract information from data sets located on personal computers or internal servers. The value of being able to extract the right information is often more important than the time it takes to search for it. However when search capabilities are offered as a service to thousands of users, constraints get much tighter: service maintainers cannot afford to let any user perform searches involving very inefficient algorithms as this may cause the service to become unresponsive to all users.
Re2 is a regex library that avoids the state explosion problem as deterministic automata are not required to be built. It also provides guarantees regarding performance of searching with regex by limiting the set of available features (for instance, backreferences are not possible with Re2). This approach is sill very practical though as the set of features offered still allows for interesting queries to be performed. Details about the principles behind Re2 can be found here (linear time search w.r.t. input size) and here (virtual machine approach, avoiding automata determinisation and therefore the state explosion problem). Traditionally Logentries used a JNI wrapper over Re2 in order to integrate it into its Java code base. Recently a library called Re2J, which is a port of Re2 to Java, was released and has now replaced Re2-Java in Logentries’ code base as it has proven to be faster at matching events than the JNI calls made by Re2-Java (see below for performance comparison).
Finally Brics is a regex library which takes advantage of deterministic automata in order to perform fast regex matching.
Re2-Java Vs Re2J Vs Brics
In terms of features, Re2J and Re2 have similar sets. Some of these features are not supported by Brics such as special escaped characters (e.g. \d, \s, etc). In terms of safety of use, Re2-Java and Re2J both avoid the state explosion problem while Brics does not. Finally regarding performance while matching events/input, Brics outperforms Re2-Java and Re2J, especially when considering large datasets. Figure 1 illustrates this.
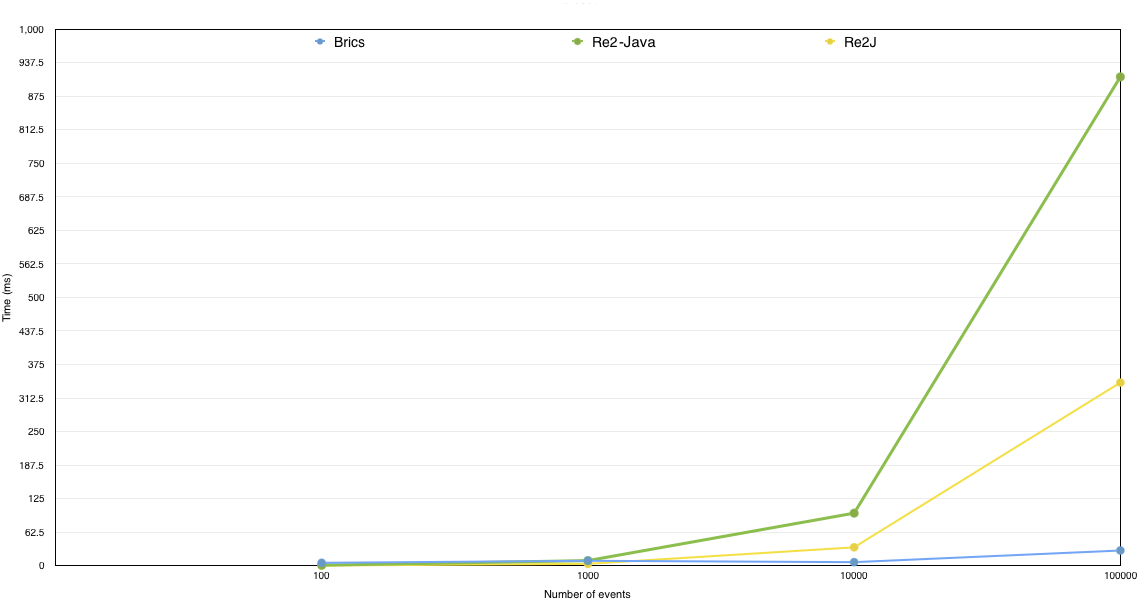
These comparisons were performed on regular expressions that all 3 libraries can handle and that are typical to Logentries customers. So even though Figure 1 data is respective to specific queries and not fully general, it does show the trend that was mostly observed:
- Re2-Java, Re2J and Brics tend to perform similarly on small datasets, i.e. less than 1000 events.
- Differences in performance start being significant when considering ten’s of thousands of events, with Brics outperforming Re2J, itself outperforming Re2-Java.
When applying regular expressions on large sequence of events, many events may not match the regex. Figure 2 shows the result of comparing Re2-Java, Re2J and Brics when no events are matched. The trend is similar to the one observe in Figure 1, with Brics being faster than Re2J, which is itself faster than Re2-Java.
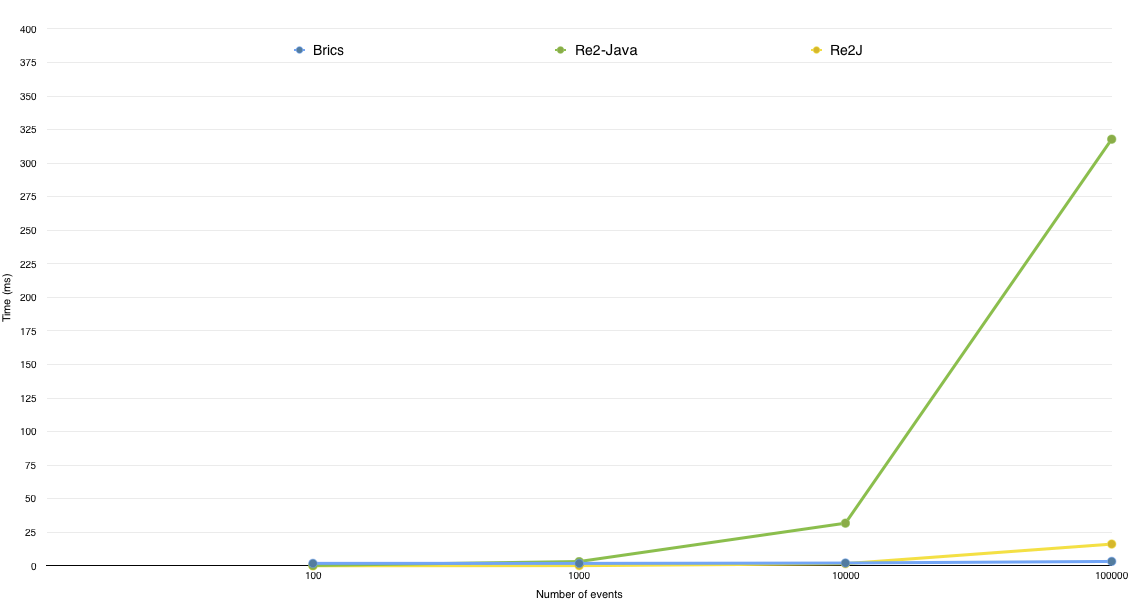
From Figure 1 and 2, Re2J appears to be more performant than Re2-Java for a similar feature set. Also Brics appears to be a good choice when it comes to performance while matching large sequences of events. However it suffers from the state explosion problem by building deterministic finite state machines and is not as feature complete as Re2J and Re2-Java. So in order to take advantage of Brics whenever possible, the following approach can be considered for a given regular expression that fits within Brics feature set:
- Try to compile the regex with Brics,
- Abort if the number of states of the automata being built goes beyond a given threshold (and go to Point 4.)
- If the size of the automata remains within the threshold, use the automata to perform matching (benefiting from Brics matching performance)
- If the size of the automata does not remain within the threshold, then fall back onto using Re2J.
Of course, for regular expressions that cannot be handled by Brics, Re2J can then be used.
In order to implement this approach, two questions remain to be answered:
- How to determine what threshold to be used?
- How to determine whether a regular expression fits within Brics feature set?
For Question 1, we considered typical regular expressions used by our users and compiled the ones that fit within Brics feature set, while monitoring the maximal size of the automata being built during this process. Figure 3 illustrates the distribution that we obtained.
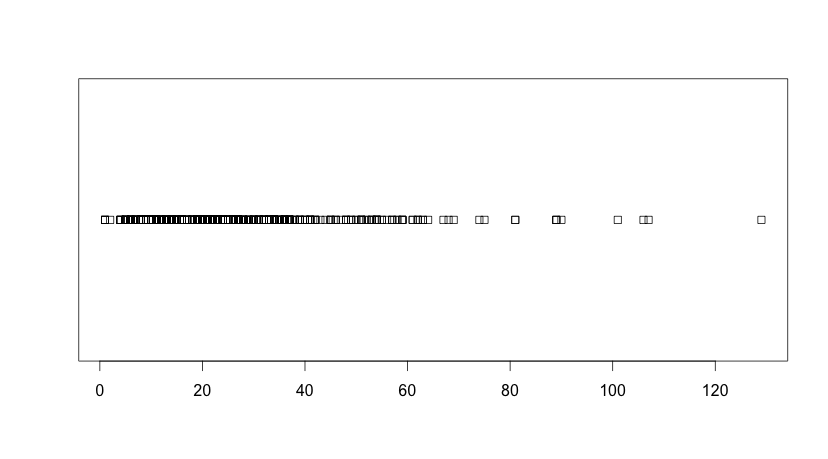
Figure 3 shows that a threshold of 80 states would capture most of our users use cases.
Question 2 is answered by leveraging our regex parser. Search queries are parsed using ANTLR. Beside generating both a Java and Javascript parser from one single language grammar, ANTLR also makes it much easier to determine whether the regular expression being parsed is valid and which features it contains. For instance considering a PCRE grammar, special escaped characters are detected and the use of Brics to apply the provided regular expression can be ruled out in this case as we know it does not handle such characters.
Conclusion
A primary concern when providing a service where users can perform searches using regular expression is to limit it to “safe” cases where the state explosion problem (inherent to automata computing deterministic automata) is avoided as well as slow matching algorithms. A Java library such as Re2J ensures such criteria. However, when applying regular expressions to millions or even billions of events, another level of performance is needed. Brics is a Java library that provides fast event matching. However, unlike Re2J, Brics may be subject to the state explosion problem. It also provides a more limited set of features. A possible strategy in this case is to consider two regex libraries and take advantage of a ANTLR parser in order to detect which library should be used for the regular expression submitted, performing fast matching when possible while having the ability to always fall back onto a safe (still quite performant) option. Safety first!
Logentries allows you to aggregate all of the data from you environment together and quickly search across that dataset with regular expressions.




