
Which Virtual Machine is Best: Google’s Compute Engine or Amazon’s EC2? It Depends.

The Internet might seem like a Wild West of chaotic connections because it often is. Companies like Google and Amazon have
been managing to create order out of the chaos for years by understanding the nature of the World Wide Web. Within the last 10 years, Google and Amazon have leveraged that understanding into a robust suite of product offerings in the field of Infrastructure-as-a- Service, or IaaS.
The cornerstone of IaaS is the virtual machines that customers can use to virtualize servers. How do you choose between these two experienced giants when the time comes for your organization to start using Cloud-based virtual machines? Both are excellent at what they do and have brought significant experience to their offerings.
The answer is, “It Depends”. There is no wrong choice to be made; but that is not to say they are identical. This article will talk about the similarities and differences between them to help you decide which provider to use.
What is IaaS? What is an Elastic Compute Cloud (EC2) or a Compute Engine?
IaaS is a cloud offering similar in nature to SaaS (Software as a Service) products like Salesforce.com. Anything, and everything, that would usually be in a corporate network data center can be subscribed to as a service. This includes everything a network needs:
- Routers
- Firewalls
- Database Servers
- File Servers
- Data Warehouses
- User Management
- Virtualized Servers
- and more….
This paper is going to review the virtual server component of IaaS. EC2 (Elastic Compute Cloud) is the name of Amazon’s virtualized server offering. Google named their virtualized server offering Google Compute Engine.
A virtual server is configured by selecting a series of configuration options. Each service (Google or Amazon) will have a slightly different set of configuration options. This brings us back to the title of the article. Which service you use really depends on the nature of options your product needs.
“IaaS: Infrastructure as a Service Anything, and everything, that would usually be in a corporate network data center can be subscribed to as a service.”
Structure of a Virtual Server
There are two major phases to running a virtual server, and they are very similar across providers. Servers are configured through a variety of options depending on the provider. Once configured, servers are launched into instances. An instance is a running virtual machine. The term “EC2”, or “EC2 server”, and “Google Compute Engine”, or “Google Compute Engine server”, is used to refer to the configuration portion. From the configuration, any number of instances can be run, and they are usually referred to as “instances”, such as an “EC2 instance” or a “Google Compute instance”.
“EC2: Elastic Compute Cloud … they are usually referred to as “instances”, such as an “EC2 instance …”
The Structure of an EC2 Server
EC2 is the king of options. There are lots of choices to make which can make Amazon’s EC2s a bit intimidating to work with. Almost all parts of the virtual server can be configured through Amazon’s substantial options list. There are two options in particular that are most relevant to our discussion here: AMIs and Instance Types.
AMI stands for Amazon Machine Image. AMIs are software configurations that are preloaded into your instance. This can be as bare bones as an operating system or as complex as a full server stack.
There are many free AMIs provided by Amazon to choose from. Beyond the free tier, machine images can be rented. Renting a machine image gives you the benefit of a well crafted stack that will be maintained as new versions are released. Renting an AMI removes the burden of maintenance from your team, and gives you a certain level of trust in the stack (although quality can vary based on vendor).
Once you have selected an image, you choose the type of machine to run on. Instance types define the virtual resources assigned to the virtual server. Amazon offers several types broken into focus and size. There are instance types focused towards general use or optimized for computing, memory, graphics, or storage. Instance types, as we will see, are largely the same across services, but Amazon does have one focused type that Google does not (at the time of this writing).
Amazon has a graphics optimized focus This category adds vGPUs (virtual Graphics Processing Units) as well as vCPUs (virtual Central Processing Units). These machines are designed to handle streaming services or heavy graphics processing. They would be excellent for encoding/transcoding media, heavy graphics processing in applications like CAD software, and server-side graphics optimization, among others. This does give Amazon a leg up for this kind of virtualized work.
Inside each focused type there are general size categories. For example, there are three size categories for general use: T2, M3, and M4. The options don’t stop there. Inside of each size category are the specific types you actually select. The below table is an example of the general use instance type M3 as of 2/12/16:
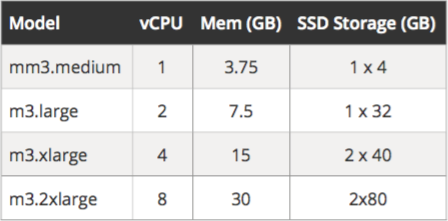
Each of those columns reflect the resources assigned to an instance based on that instance type. The instance type is actually the model name on the far left: m3.medium, m3.large, m3.xlarge, m3.2xlarge. Each model represents a virtual server with more resources than the one above it.
You would be hard pressed not to find a configuration for an EC2 instance to suit your needs. From rented machine images to scales of preconfigured hardware profiles, there are many options to choose from. As we will see in the next section, Google chose to keep the process as simple as possible, and limited the options available.
The Structure of a Google Compute Engine Server
Google takes a different, but no less robust, approach to configuring virtual servers. The Google Compute Engine is easier to use to set up an instance, but provides fewer configuration options up front. When creating a Google virtual server the two pieces that parallel the Amazon process are the boot disk and instance type.
When first creating an instance, the boot disk is the OS you want the machine to have. This eschews the complexity of the AMI for a simpler choice of free OS options. There is no marketplace akin to Amazon to find full stack implementations. Google does provide many options to import more specialized boot disks, such as an existing AMI or a VirtualBox configuration. Once you have a server running, you can configure it, then set its image aside for future servers to use as a boot disk.
Instance type selection is very similar to Amazon’s. There are a set of pre-defined virtual hardware configurations to choose from. The focused categories for Google Compute Engines are: standard, high CPU, high memory, and shared core. Inside each focus are the specific instance types to choose from with tiers increasing in power and cost as you go. This is simpler than Amazon since there is no intermediary class category, like M3 from above. For example, here some of the standard instance types as of 2/2/16:
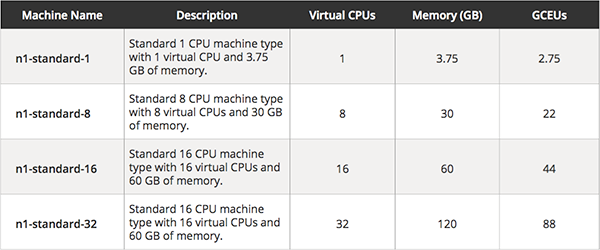
Google does have one optional route that Amazon does not. Google allows you to ignore the pre-configured instance. Google let’s you create a custom instance type where you can manually select the number of cores and amount of memory you want on that machine. This is a nice feature, especially if you have very specific requirements that none of the predefined types meet.
Virtual Server Summary
• Amazon EC2s and Google Compute Engines are very similar in structure. Both are configured via a software and hardware configuration.
• Amazon EC2 software configurations (called AMIs) range from free OS only versions to third- party full stack maintained configurations.
• AGoogle Compute Engine software configurations all start with bare-bones OS installations. However, further configurations can be uploaded from AMIs, VirtualBoxes, or previous Compute Engine instances.
• Hardware configurations on both services are broken into focused categories such as general purpose, storage heavy, or memory optimized.
• Amazon has a GPU focused hardware configuration that Google does not for heavy graphics processing or streaming applications.
• Google allows for a completely custom hardware configuration option, which Amazon does not.
“Google let’s you create a custom instance type where you can manually select the number of cores and amount of memory you want on that machine.”
Geography
Geography plays an important part in any conversation of virtualized servers. The three biggest ways in which geography comes into play are summarized below:
1. Latency – Digital information still needs to ow over physical networks. In the case of simple applications, using a server hosted on the other side of the country or on another continent may have little noticeable impact. As system complexity and data requirements grow, physical distance becomes an increasingly limiting factor.
2. Disaster Recovery – Unfortunately, things do go wrong sometimes, and where it goes wrong matters. If the physical location where resources are hosted has an emergency, it can lead to resources being lost. Having multiple physical locations to host the same or similar resources is protection against a disaster at any one.
3. The Law – The physical location is going to be under the jurisdiction of some legislative body, whether it is a state, province, country, or some combination. Not all laws will honor ownership the same way, and in some cases, having a data center at a certain location can open the entire system to government intervention.
Amazon and Google are multi-national organizations with customers in and across widely disparate geographical areas. Their offerings reflect this with the use of zones and regions in the configuration of their virtualized resources. When creating instances of your virtual servers you will have to identify the Regions and Zones you want your instances created in.
Zones, called Availability Zones in Amazon parlance, are specific locations. For both services, Zones are gathered into Regions. Regions represent large geographic areas. Zones are connected to each other through very low latency connections designed to make their physical distances indistinguishable from each other to end users. Regions are not connected directly and isolated by design.
The Regions in both services are largely, although not exactly, the same. The Amazon Regions are in Eastern US, Western US, Western Europe, Asia Pacific, and Southern America. The Google Regions are in Eastern US, Central US, Western Europe, and Eastern Asia.
Amazon and Google use Zones and Regions in much the same way to address latency and disaster recovery. Putting virtualized servers in more than one zone means you can share processing load across servers. Having servers
in multiple regions means servers can be used closest to the largest concentrations of users to reduce latency as much as possible. Having multiple instances in different regions and zones protects your organization in the case of a disaster or server fault.
Amazon differs from Google in addressing issues of legal restrictions. Amazon has two other special Regions designed to help customers with more restrictive legal entities: China and the US Government. These Regions are isolated in the same manner as other Regions. Unlike other Regions, these Regions can not be connected to in any way from an outside Region.
In the case of China, this protects customers from legal issues that could compromise data in other Regions. In the case of the US Government, Amazon provides GovCloud. GovCloud is a unique Region tailored to meet the stricter guidelines and laws required for companies doing business with government entities. If your organization needs to work with government offices, or companies bound by government restrictions, then Amazon is the only safe choice based on Region and Zone configurations.
Geography Summary
• Regions and Zones assist with the 3 main issues that virtualization addresses: Latency, Disaster Recover, and Laws.
• Across Google and Amazon:
° Regions are large geographically areas made up of specific locations called Zones (or Availability Zones).
° Zones are connected by special low latency connections.
° Regions are isolated from each other.
° Both companies use this Region and Zone structure to help customers resolve problems of latency and disaster recovery.
• Only Amazon has special Regions to resolve the issue of legal regulations in geography:
° China
° GovCloud
“Putting virtualized servers in more than one zone means you can share processing load across servers. Having servers in multiple regions means servers can be used closest to the largest concentrations of users to reduce latency as much as possible.”
Network
Like Regions and Zones, both services are very similar in the networking options for their virtual servers. Also like Regions and Zones, Amazon has one extra trick up its sleeve that Google has not yet caught up to.
Both services will provide everything you need for virtual server networking. Virtual server instances will automatically have internal IP addresses and names that can be used for DNS purposes. External IPs can be assigned to instances in both services.
IP management is robust in both services. Internal IP addresses are automatically assigned to instances. External IP addresses can be assigned to instances.
Google and Amazon leverage the dynamic nature of virtual computing to help protect their customers in the case of an instance failing with an external IP. IP addresses that are externally accessible are purposefully fluid in nature on both providers. Amazon calls the flexible external IP model “Elastic IP”, where as Google refers to it as “Static External IPs”. They both describe an external IP that can easily be switched from one instance to another. This is to protect customers when an instance fails, needs to be shut down, or to support rolling maintenance.
The only real difference between the two services when it comes to virtual networking is Amazon’s Enhanced Networking. This is accomplished using “single root I/O virtualization” (SR-IOV). It should technically be possible to emulate this in a Google Compute Engine instance but it is not a standard option and would require significant advanced knowledge to implement.
The simplest explanation of SR-IOV technology is that it allows network traffic to bypass virtualization software. The virtual server
is able to operate against virtual network interfaces directly and separately in a way similar to physical hardware interfaces. Each virtual interface has its own address, and
isn’t dependent on the software to direct traffic. The result is near-physical hardware performance without the overhead of virtualization software. In practical use, this is for high-availability/extremely low latency applications. Most software applications will not need this level of optimization.
“The only real difference between the two services when it comes to virtual networking is Amazon’s Enhanced Networking.”
Network Summary
• Virtual server networking is handled in a very similar fashion across Google and Amazon.
• Externally facing IP addresses can easily be switched from virtual instance to virtual instance in both services.
• Amazon provides a unique service called “Enhanced Networking” on some of its instances that provides near physical hardware performance. However, this level of optimization is only needed for specialized systems.
Disk
Amazon and Google both use persistent disk storage. Persistent disk storage refers to the fact that the storage is not directly tied to the life of an instance. These disks can be connected to any valid instance and will maintain themselves while the instance is not running. Amazon calls the service “Elastic Block Storage” (EBS), while Google uses the simpler moniker “Block Storage”. As we have seen before, options are divided into tiers of increasing cost and power.
Amazon offers:
• General Purpose SSD – Best suited for boot volumes, small to mid sized databases, and test/dev instances.
• Provisioned IOPS SSD – This is the standard volume type that is most useful for the high I/O performance required of most applications. This is also the best storage type for databases of any signi cant size.
• Magnetic – More cost effective than the other two but much less performant. This is best suited for infrequent use.
Google offers:
• Standard Persistent Disks (HDD) – Designed for bulk storage of data and sequential I/O operations. These are best suited for boot volumes, file storage, and small to mid sized databases.
• Solid State Persistent Disks (SSD) – Data that is going to be heavily used by an application and requires swift I/O performance belongs here. This would be well suited to web pages, large databases, and caches.
Disk storage options is one area where Google outshines Amazon in the breadth of options. Google offers Local Storage Solid State Drives. Unlike persistent state drives, local drives are directly connected to the instance. They can not be connected to a separate instance in the same way a persistent drive is. These drives are also bound to lifecycle of the instance and are unavailable if the instance is not running. The benefit is hardware level performance and the fastest I/O possible. These are well suited for situations where extreme I/O performance is required.
Disk Summary
• Both providers use persistent storage volumes that exist independent of a particular instance and communicate with an instance over the network.
• Both providers have different tiers to account for performance needs and corresponding costs.
• Amazon has a low power option for data that is very infrequently accessed.
• Google provides storage volumes that can be directly connected to an instance and not connected over the network. These disks provide near hardware level performance.
“Disk storage options is one area where Google outshines Amazon in the breadth of options.”
Pricing
An actual cost comparison between the two services is almost impossible within the scope of this article. Costs associated with an EC2 instance or a Google Compute instance are tied specifically to the resources used, and there is no general comparison that could be made. Estimating cost is so specific. and potentially complicated that both providers have calculators for that purpose – Amazon and Google.
It is possible to generalize on the nature of how costs are calculated. Both providers calculate cost based on usage. Depending on the service being used, the cost will correlate to time or quantity. For example, instances might have a cost for the length of time they are running, while the attached storage will have a cost based on the amount of data stored. Each service gears cost towards charging customers only for what is used.
Each provider does provide unique options with which to manage the cost. In the case of Amazon, this is a set of options tied to the life of the instance. Google goes an entirely different direction and provides a discount to customers based on the amount of time their services are used.
Amazon has different cost options depending on the nature of the instances running time:
• On Demand – This is the option most commonly associated with virtualized servers. Costs are based on how long and how many servers are running.
• Reserved – There are significant discounts available with reserved instances. Reserved instances involve pre-paying for 1 to 3 years of expected service. If the virtual servers use can be closely estimated then up to 75% of the cost can be saved by pre-paying.
• Spot – This is the most cost effective option. The other two options assume a standard level of service. Spot instances are charged based on available computing power at the time. In exchange for a varied amount of processing power, the cost of that processing power is reduced.
Additionally, you can pay extra for dedicated instances and dedicated hosts. In this case, virtual resources, and potentially physical hardware, is set aside for one customer’s exclusive use. The resources being used aren’t held in pools that are shared with other customers.
Google has a much simpler pricing model. Servers are all considered on-demand and charged the same fee. The unique feature of Google’s model is the sustained use discount. Customers receive discounts for using a Compute Engine more than 25% of the month. The discount can extend all the way to a 30% effective discount for using an instance up to 100% of the month.
There is one additional pricing category for the Compute Engine that can significantly reduce the cost for non-mission critical instances. Customers can create preemptible instances. A preemptible instance can be shut down by Google whenever the computing power it is using is needed by something else. These instances are great for batch processing or maintenance activities that can be interrupted and continue once the instance restarts.
Pricing Summary
• Both providers use a pricing model that charges customers only for resources used (in most cases).
• Amazon provides customers the opportunity for dedicated instances when performance is more important than cost.
• Amazon gives customers discounts for reserving computing resources ahead of time or by limiting themselves to pools of available resources.
• Google discounts the cost of instances based on the amount of usage they get in a month.
• Google significantly reduces the cost of an instance if it can be preempted and shut down when it’s resources are needed elsewhere.
The Environmental Friendly Choice
There is one feature that Google can claim that Amazon has no correlation for. Google’s infrastructure services are carbon-neutral. Google claims to use less energy to run its infrastructure than competitors. They also state that 35% of their resources come from renewable resources. If environmental impact is an important consideration for your organization, then Google is clear the winner.
Conclusion
Both virtualized servers will work for your organization. The Compute Engine and EC2 are very similar on the surface. It is the specific nuances of each service that should guide your decision. If your organization has highly specific needs, or heavily optimized performance, Amazon’s massive breadth of options is going to work best. For most general needs, or if your organization needs standard optimizations, then Google’s model for discounts based on extended use is very compelling.
In the end, you can’t go wrong with either provider. Google and Amazon provide world-class service built on experience and expertise. You can rest assured that whichever provider you choose they will be able to make your virtualization strategy successful.
Logentries provides tools for both providers to assist you in monitoring your virtual machines:
• Logentries Linux Agent: A simple open source program that automates the collection and forwarding of log events.
• Logentries Windows Agent: Agent preforming collection and forwarding for Windows systems.
• Google Cloud Platform: With the Google Cloud Platform integration from Logentries, you can import logs from the Google Cloud Platform to your Logentries account.
• OpsStream for AWS CloudWatch: OpsStream is a free service provided by Logentries that collects information about AWS services such as EC2, EBS, RDS, and CloudWatch.




