

In the old days when transactional behavior happened in a single domain, in step-by-step procedures, keeping track of request/response behavior was a simple undertaking. However, today one request to a particular domain can involve a myriad of subsequent asynchronous requests from the starting domain to others. For example, you send a request to Expedia, but behind the scenes Expedia is forwarding your request as a message to a message broker. Then that message is consumed by a hotel, airline and car rental agency that responds asynchronously too. So the question comes up, with your one request being passed about to a multitude of processing consumers, how do we keep track of the transaction? The answer is: use a Correlation ID.
Allow me to elaborate.
Working with a Correlation ID
A Correlation ID, also known as a Transit ID, is a unique identifier value that is attached to requests and messages that allow reference to a particular transaction or event chain. The Correlation Pattern, which depends on the use of Correlation ID is a well documented Enterprise Integration Pattern. A Correlation ID is defined as a non-standard HTTP header and is part of the Java Messaging Service (JMS). However, attaching a Correlation ID to a request is arbitrary. You don’t have to use one. But if you are designing a distributed system that incorporates message queues and asynchronous processing, you will do well to include a Correlation ID in your messages.
Figure 1 below describes a situation in which using a Correlation ID provides significant benefit. Figure 1 describes a fictitious travel reservation system that can make a hotel, car rental and airline reservation on behalf of a client. The client can be a human being or another computing system.
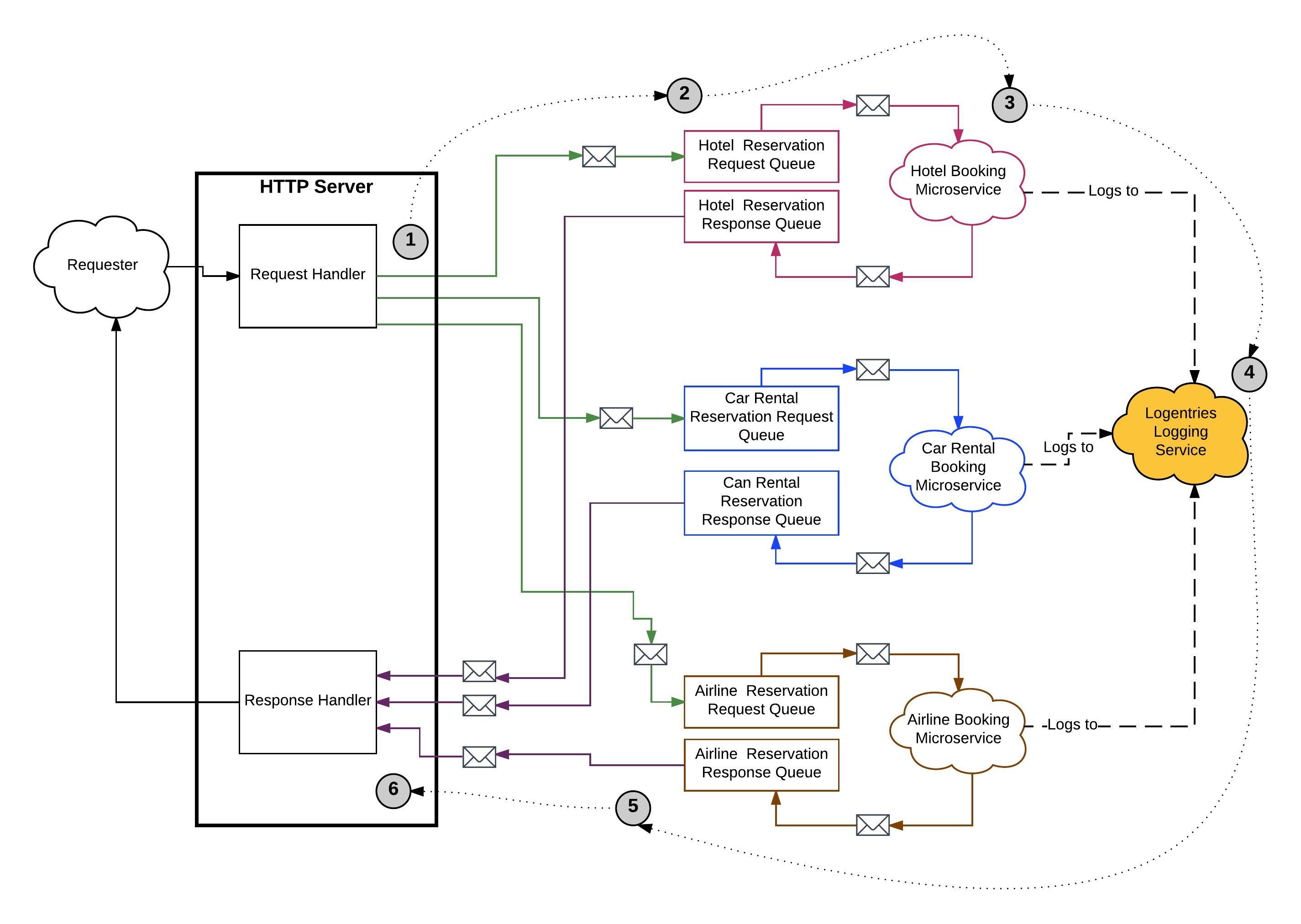
The system described above in Figure 1 accepts a request that describes reservations among three distinct systems: a hotel system, for a car rental system and an airline system. The logical flow described above is as follows: (1) A request is sent to Request Handler that that converts the information in the request into three messages. (2) One message describes the reservation parameters for a hotel booking is sent to a message queue dedicated to hotel booking messages. Another message describing the car rental is sent to the car rental message queue. The third message describing the airline reservation is sent to the airline reservation queue. (3) A microservice dedicated to each booking service is listening on the relevant queue for incoming messages. The microservice retrieves a message from its queue, does its work and logs information to the logging service as the work progresses (4). When a microservice completes its work, the reservation result is sent as a message to the response queue (5). The response handler pulls messages from the response queue and when all three expected response messages relevant to the given reservation are retrieved, (6) the response handler aggregates the information in the three reservation messages into a single response to the requester.
The outstanding question is, given all the messsage activity happening on a given response queue, how does the response handler know which response message is relevant to the given reservation? This is where the Correlation ID comes into play.
Assigning a CorrelationID
As you’ve just learned a Correlation ID is the unique identifier that binds messages to a transaction. In this case the transaction is a combination of booking requests to a hotel, car rental and airline microservices. In our scenario, the request handler creates and assigns a Correlation ID just before it splits up the single request into the three subsequent messages destined to their respective message queues. (Please see Figure 2, below.)
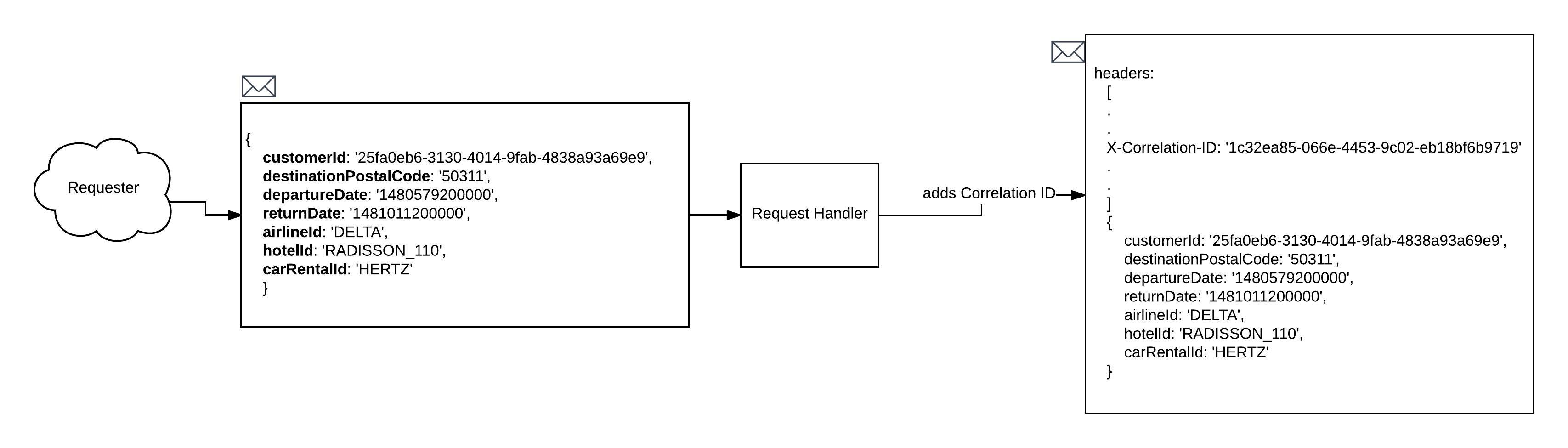
By convention a Correlation ID is passed in the header of a request or message. The often used, but non-standard field name to use in the header is, X-Correlation-ID. Figure 3 below shows how the Correlation ID is then propagated onto the subsequent messages sent to each reservation microservice.
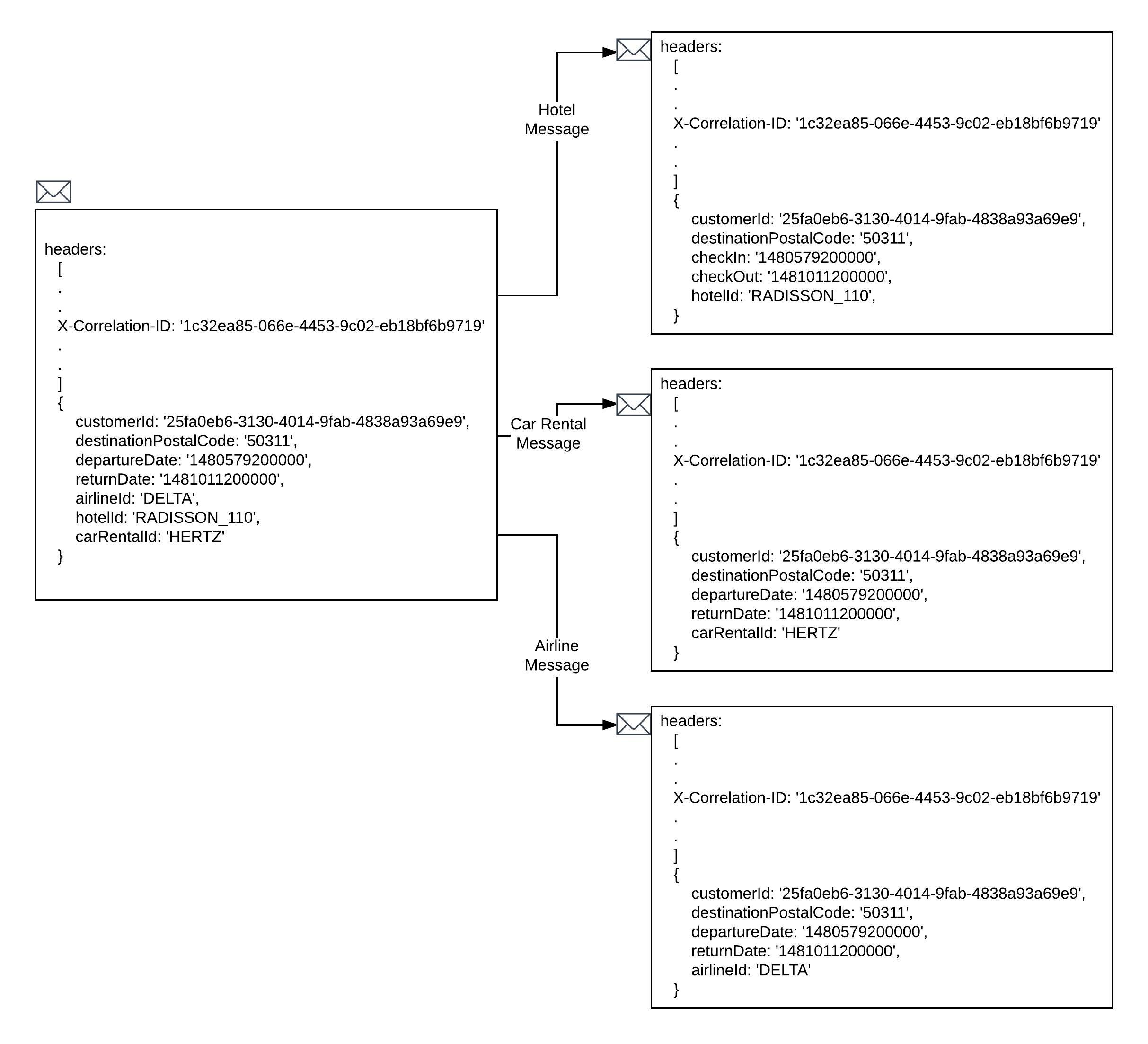
The messages going the each distinct reservation queue will have Correlation IDs inserted in the header., Intelligence in the microservice that processes these messages from a reservation queue will move the given Correlation ID downstream should subsequent message propagation occur. Also, the microservice will include the Correlation ID in any log entry made. When it comes to logging, the Correlation ID will be the glue that holds the transaction information together.
Where and when is the Correlation ID assigned?
A good rule of thumb is this:
Assign the Correlation ID as soon as you can. And, if you find that you are passed a Correlation ID, use it.
Using a Correlation ID in Logs
Correlation IDs are particularly powerful when it comes to log activity. As mentioned previously, a CorrelationID is the glue that holds transaction information together. As you may remember from our discussion in Figure 1 above, part of the work that a booking microservice does is to log event activity to a common logging service such as Logentries. Providing a CorrelationID with a log entry provides a key by which auditing can be implemented. Remember, a microservice will be processing thousands of messages. The only thing a microservice knows about is the information passed in the message it processes. The microservice just does not see the Big Picture. That’s why they’re called microservices. They process one message at time. How these messages relate to other things is not a concern. Understanding things such as context and audit trail is the work of logs. Logging is where a Correlation ID becomes invaluable.
Remember please the system architecture described in Figure 1 above has every microservice writing to a common log service. Thus, should something go wrong, one of the first things we will do is look at the logs. All the information we need is there, if we can find it. Including a Correlation ID in event logging binds a workflow or transaction together. In a failure situation in the system, all we need to do is to query the logs according to the Correlation ID to get a unified understanding of the transactional activity among the variety of microservices in play. Then, having a unified understanding the events, we can determine likely cause. If we did not have the Correlation ID, understanding the course of events would be harder, maybe impossible to determine.
How can I use a CorrelationID in an HTTP Request?
A growing trend among enterprise systems is to inspect for the existence of the Correlation ID in the header of incoming requests and, should the Correlation ID exist, then propagate the submitted CorrelationID downstream on the server side. So, if you are writing client side code and want to make a Correlation ID known to the server, include it in the header of your HTTP request by using the common, but non-standard field name, X-Correlation-ID.
Putting It All Together
The notion of a Correlation ID is simple. It’s a value that is common to all requests, messages and responses in a given transaction. With this simplicity you get a lot of power.
Asynchronous programming by nature is hard to track. There is no guarantee of the sequence of events. Things happen when they happen, sometimes sooner, sometimes later, sometimes not at all. Having a common “tag” among elements in a transaction allows a common reference by which logging and auditing can happen. When something goes wrong in an asynchronous, distributed system, troubleshooting is more than piecing together timestamps in a log. Including a Correlation ID in requests and messages and entering the Correlation ID as part of the standard practice for logging, provides the glue that is needed to create a coherent, understandable audit of events.
When you can group a transaction’s events under a unifying value, the Correlation ID, you can spend your time fixing the problem rather than finding the problem. Without a Correlation ID, well… there is a saying, “if you put a chimpanzee in front of typewriter for eternity, eventually the animal will type out Hamlet.” The same could be said for logging without a Correlation ID, except none of us will be here for eternity. Use a Correlation ID. You will be glad you did.




