
Editor’s note: We had planned to publish our Hacky Holidays blog series throughout December 2021 – but then Log4Shell happened, and we dropped everything to focus on this major vulnerability that impacted the entire cybersecurity community worldwide. Now that it’s 2022, we’re feeling in need of some holiday cheer, and we hope you’re still in the spirit of the season, too. Throughout January, we’ll be publishing Hacky Holidays content (with a few tweaks, of course) to give the new year a festive start. So, grab an eggnog latte, line up the carols on Spotify, and let’s pick up where we left off.
Santa’s task of making the nice and naughty list has gotten a lot harder over time. According to estimates, there are around 2.2 billion children in the world. That’s a lot of children to make a list of, much less check it twice! So like many organizations with big data problems, Santa has turned to machine learning to help him solve the issue and built a classifier using historical naughty and nice lists. This makes it easy to let the algorithm decide whether they’ll be getting the gifts they’ve asked for or a lump of coal.
Santa’s lists have long been a jealously guarded secret. After all, being on the naughty list can turn one into a social pariah. Thus, Santa has very carefully protected his training data — it’s locked up tight. Santa has, however, made his model’s API available to anyone who wants it. That way, a parent can check whether their child is on the nice or naughty list.
Santa, being a just and equitable person, has already asked his data elves to tackle issues of algorithmic bias. Unfortunately, these data elves have overlooked some issues in machine learning security. Specifically, the issues of membership inference and model inversion.
Membership inference attacks
Membership inference is a class of machine learning attacks that allows a naughty attacker to query a model and ask, in effect, “Was this example in your training data?” Using the techniques of Salem et al. or a tool like PrivacyRaven, an attacker can train a model that figures out whether or not a model has seen an example before.
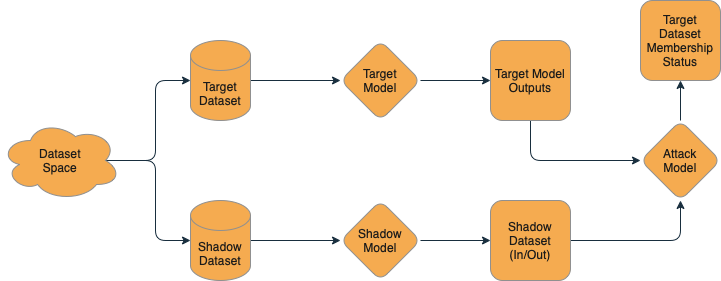
From a technical perspective, we know that there is some amount of memorization in models, and so when they make their predictions, they are more likely to be confident on items that they have seen before — in some ways, “memorizing” examples that have already been seen. We can then create a dataset for our “shadow” model — a model that approximates Santa’s nice/naughty system, trained on data that we’ve collected and labeled ourselves.
We can then take the training data and label the outputs of this model with a “True” value — it was in the training dataset. Then, we can run some additional data through the model for inference and collect the outputs and label it with a “False” value — it was not in the training dataset. It doesn’t matter if these in-training and out-of-training data points are nice or naughty — just that we know if they were in the “shadow” training dataset or not. Using this “shadow” dataset, we train a simple model to answer the yes or no question: “Was this in the training data?” Then, we can turn our naughty algorithm against Santa’s model — “Dear Santa, was this in your training dataset?” This lets us take real inputs to Santa’s model and find out if the model was trained on that data — effectively letting us de-anonymize the historical nice and naughty lists!
Model inversion
Now being able to take some inputs and de-anonymize them is fun, but what if we could get the model to just tell us all its secrets? That’s where model inversion comes in! Fredrikson et al. proposed model inversion in 2015 and really opened up the realm of possibilities for extracting data from models. Model inversion seeks to take a model and, as the name implies, turn the output we can see into the training inputs. Today, extracting data from models has been done at scale by the likes of Carlini et al., who have managed to extract data from large language models like GPT-2.

In model inversion, we aim to extract memorized training data from the model. This is easier with generative models than with classifiers, but a classifier can be used as part of a larger model called a Generative Adversarial Network (GAN). We then sample the generator, requesting text or images from the model. Then, we use the membership inference attack mentioned above to identify outputs that are more likely to belong to the training set. We can iterate this process over and over to generate progressively more training set-like outputs. In time, this will provide us with memorized training data.
Note that model inversion is a much heavier lift than membership inference and can’t be done against all models all the time — but for models like Santa’s, where the training data is so sensitive, it’s worth considering how much we might expose! To date, model inversion has only been conducted in lab settings on models for text generation and image classification, so whether or not it could work on a binary classifier like Santa’s list remains an open question.
Mitigating model mayhem
Now, if you’re on the other side of this equation and want to help Santa secure his models, there are a few things we can do. First and foremost, we want to log, log, log! In order to carry out the attacks, the model — or a very good approximation — needs to be available to the attacker. If you see a suspicious number of queries, you can filter IP addresses or rate limit. Additionally, limiting the return values to merely “naughty” or “nice” instead of returning the probabilities can make both attacks more difficult.
For extremely sensitive applications, the use of differential privacy or optimizing with DPSGD can also make it much more difficult for attackers to carry out their attacks, but be aware that these techniques come with some accuracy loss. As a result, you may end up with some nice children on the naughty list and a naughty hacker on your nice list.
Santa making his list into a model will save him a whole lot of time, but if he’s not careful about how the model can be queried, it could also lead to some less-than-jolly times for his data. Membership inference and model inversion are two types of privacy-related attacks that models like this may be susceptible to. As a best practice, Santa should:
- Log information about queries like:
- IP address
- Input value
- Output value
- Time
- Consider differentially private model training
- Limit API access
- Limit the information returned from the model to label-only




