In a previous post I illustrated a very basic data flow dependency graph. This graph was meant to describe the order (and thus dependencies) of memory read and write operations within the context of a given function. While this graph may be useful in some circumstances, the simple fact that it's limited to a specific function means that there will be no broad applicability or understanding of the program as a whole. To help solve that problem, it makes sense to try to come up with a way to describe data flow dependencies in a manner that crosses procedural boundaries. By doing this, it is possible to illustrate dependencies between functions by analyzing both a function's formal parameters (both actual arguments and global variable references) and output data (such as its return value).
To better understand this, let's take an example C program as illustrated below:
typedef struct _list_entry
{
struct _list_entry *next;
struct _list_entry *prev;
} list_entry;
list_entry *list = NULL;
list_entry *add()
{
list_entry *ent = (list_entry *)malloc(sizeof(list_entry));
if (list)
{
ent->prev = list->prev;
ent->next = list->next;
if (list->prev)
list->prev->next = ent;
if (list->next)
list->next->prev = ent;
}
list = ent;
return ent;
}
void remove(list_entry *ent)
{
if (ent->prev)
ent->prev->next = ent->next;
if (ent->next)
ent->next->prev = ent->prev;
free(ent);
}
void thread(void *nused)
{
while (1)
{
list_entry *ent = add();
remove(ent);
}
}
int main(int argc, char **argv)
{
CreateThread(NULL, 0, (LPTHREAD_START_ROUTINE)thread, NULL, 0, NULL);
CreateThread(NULL, 0, (LPTHREAD_START_ROUTINE)thread, NULL, 0, NULL);
thread(NULL);
}
This program is a very simple (and intentionally flawed in more ways than one) linked list implementation. The basic idea is that three threads run simulatenously, each inserting and removing a node from the list as fast as possible. In another post in the future I'll talk about how we can use data flow analysis to attempt to identify data consistency issues in a multi-threaded application (such as this), but for now, let's focus simply on doing interprocedural data flow analysis. Keep in mind from our previous post that there are two types of data flow dependencies, a value dependency and an address dependency. A value dependency, denoted by blue edges, means that one instruction depends on the value read from memory (Example: mov [ebp-0x4],eax depends on mov eax,[ebp 0x8] for the value of eax). An address dependency, denoted by red edges, means that a value read from memory is being used to reference another location in memory (Example: mov [ecx],eax depends on mov ecx,[edx] since ecx is being used as a pointer that was obtained through edx).
When we compile the example program, we can use our existing intraprocedural data flow analysis approach to identify localized data dependencies using a disassembler specific to the architecture that we compiled the program for. While this works perfectly fine, it can end up being more complicated than it would otherwise need to be. An alternative approach that has been used in other projects (such as valgrind) is to take the architecture specific code and translate it into a more universal instruction set. By doing this, we can write our tools in a manner that allows us to not care about the underlying architecture, thus masking a degree of complexity and code duplication. I'm not going to go into the specifics of the instruction set that MSRT uses at this point, but the important matter is that it boils down all operations that result in memory access into a load or store operation (potentially using a temporary pseudo-register when necessary). This allows us to more easily determine data flow dependencies. With this in mind, let's try to understand the graph that is generated when we do an interprocedural data flow analysis on the program displayed above:
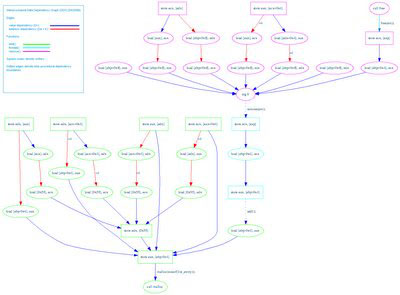
At first glance this graph is probably pretty confusing, so let's try to work our way out from a known point so that we can better understand what's going on. First, it's important to understand that the direction of the edges denotes that u depends on v where the edge is pointing to v. Knowing this, it probably makes sense to start at the only node that isn't dependent on anything else: the call malloc node.
If we work our way backwards from this node, we can begin to better understand how the nodes relate to the source code. For instance, we see that the node store eax, [ebp-0x4] depends on call malloc. The reason for this dependency is because malloc is the last node to modify eax. If we look at the source code, we see that the first thing done after malloc returns is that the ent local variable is set to the return value. As one would expect, the ent local variable is located at ebp-0x4. If we follow the dependencies backward one node further to store edx, [0x55], we can correlate this to the setting of the global variable list (which, in this disassembly, is represented as existing at address 0x55). Try walking back further to see if you can associate other portions of the data dependency graph with areas of the source code within the add function.
Back on topic, though, I want to focus on illustrating how the interprocedural dependency relationships are conveyed. As we can see, each of the three functions is identified by a different node color. add is represented by green, thread is represented by cyan, and remove is represented by magenta. The dotted line between nodes of a different color represents an interprocedural dependency. Let's focus on the dependency between add and thread first.
As we know from the source code, the thread function takes the return value from add and passes it to remove. This is conveyed in terms of a data flow dependency by noting that eax is set prior to returning from add. Therefore, the use of eax within the thread function implies an interprocedural value dependency between the load [ebp-0x4], eax instruction in add and the store eax, [ebp-0x4] instruction in thread.
Furthermore, if we follow the value dependencies up from that point, we can see that the return value from add is subsequently passed as the first actual argument to remove. By virtue of this fact, an interprocedural value dependency exists between the the first argument of remove and the return value of add.
In the interest of not writing a book, I'm going to cut this post a bit short here. In closing, there are many interesting things that you can learn by understanding the different aspects of a data flow graph. For instance, you can begin the process of simplifying the graph. One way of simplifying the graph would be through value dependency reduction. This means that any time you have the scenario of u depends on v for value and v depends on z for value, you can reduce it to u depends on z for value. Try it out with the sample graph above and see if it makes sense. Another interesting thing you can do is translate the graph into a series of equations or statements that describe the data flow process by simply turning each of the edges into a function of the node (or derived node) that they depend on.
At the moment MSRT doesn't have full support for some of the things described in this post (the graph was actually generated using a combination of manual and automated analysis). Hopefully this post wasn't too incoherent =) It's a tad bit late...
