
About two years ago, Metasploit implemented the microphone recording feature to stdapi thanks to Matthew Weeks. And then almost a year ago, we actually lost that command due to a typo. We, and apparently everyone else, never noticed that until I was looking at the webcam API again. But of course, we quickly repaired the missing feature, and now "record_mic" is back in business as a meterpreter command in both Windows and Java meterpreter. And yes, that means you get to use it in all kinds of platforms -- Windows, OSX, Linux, etc.
Frankly, I am quite surprised it took us this long to catch the problem, because that also means nobody was using it. Perhaps this is because every professional penetration tester is a gentleman, not willing to tap into meetings via a compromised machine, and listen to people's conversations. Or perhaps it's because "record_mic" isn't convenient enough to use, and most people don't have an idea how to process a bunch of WAV files? Well, let's try to improve that.
"You know how to fight six men. We can teach you how to engage six hundred"
Since "record_mic" is a meterpreter command, that means in Metasploit Pro, you can only deploy that against your targets ONE BY ONE in the web GUI. Or, you borrow the "run_all_post.rc" resource script, and then enable microphone recording in every shell in msfconsole. To extend that capability a little bit further, "record_mic" is no longer just a meterpreter command, it can also be deployed as a post module. That way, in Metasploit Pro, you can select ALL of your targets, or only some of them very easily -- like the following example:
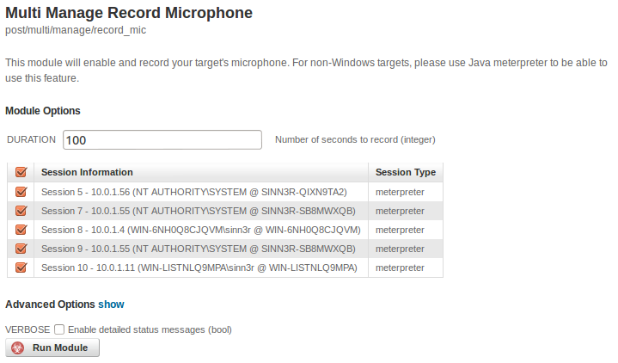
"I'll analyze it... with SCIENCE!!!"
Say you've successfully recorded a bunch of people's meetings through their compromised laptops in WAV, time to extract information. Maybe there's some goodies in these files -- passwords, company secrets, operations, future plannings, spendings, etc -- you never know. However, this can be a rather time consuming task, so it's best to kind of automate it and narrow down interesting recordings. You can try to do it with some kind of speech API, for example: AT&T speech API, Google Voice, Speech2Text, etc. I'll use AT&T speech API for the following demonstration. The proof-of-concept script can be downloaded [here].
Make sure you have a valid AT&T Speech API/secret key before trying this out.
To use this PoC, issue the following command:
$ ./d3v_wav_analyze.rb -i ~/.msf4/loot/ -o /tmp -a [API_KEY] -s [SECRET_KEY]
The script will use the speech API to translate each WAV file into text. And then, we can narrow down interesting findings by looking for certain keywords, such as: username, password, passcode, passphrase, birthday, social security, account, etc, etc. Here's a basic example:
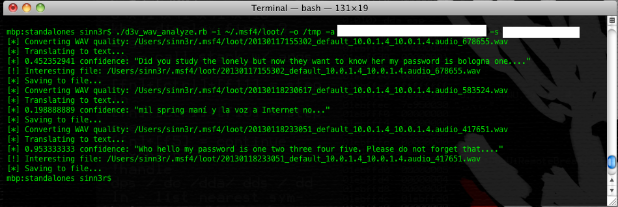
The quality of your results depends on several things: How clearly the sound was captured, how many keywords you're searching, etc, etc. I leave the rest of the experiment to you guys.




