New to writing regular expressions? No problem. In this two-part blog series, we’ll cover the basics of regular expressions and how to write regular expression statements (regex) to extract fields from your logs while using the custom parsing tool. Like learning any new language, getting started can be the hardest part, so we want to make it as easy as possible for you to get the most out of this new capability quickly and seamlessly.
The ability to analyze and visualize log data — regardless of whether it’s critical for security analytics or not — has been available in InsightIDR for some time. If you prefer to create custom fields from your logs in a non-technical way, you can simply head over to the custom parsing tool, navigate through the parsing tool wizard to find the “extract fields” step, and drag your cursor over the log data you’d like to extract to begin defining field names.
The following guide will give you the basic skills and knowledge you need to write parsing rules with regular expressions.
What Are Regular Expressions?
In technical applications, you occasionally need a way to search through text strings for certain patterns. For example, let’s say you have these log lines, which are text strings:
May 10 12:43:12 SECRETSERVERHOST CEF:0|Thycotic Software|Secret Server|10.9.000002|500|System Log|7|msg=The server could not be contacted. rt=May 10 2021 12:43:12
May 10 12:43:41 SECRETSERVERHOST CEF:0|Thycotic Software|Secret Server|10.9.000002|500|System Log|7|msg=The RPC Server is unavailable. rt=May 10 2021 12:43:41
You need to find the message part of the log lines, which is everything between “msg=” and “rt=”. With these two log lines, I might hit the easy button and just copy the text manually, but clearly, this approach won’t work if I have hundreds or thousands of lines from which I need to pull the field out.
This is where regular expression, often shortened to regex, comes in. Regex gives you a way to search through text to match patterns, like “msg=”, so you can easily pull out the text you need.
How Does It Work?
I have a secret to share with you about regular expression: It's really not that hard. If you want to learn it in great depth and understand every feature, that’s a story for another day. However, if you want to learn enough to parse out some fields and get on with your life, these simple tips will help you do just that.
Before we get started, you need to understand that regex has some rules that must be followed. The best mindset to get the hang of regex, at least for a little while, is to follow the rules without worrying about why.
Here are some of the basic regular expression rules:
- The entire regular expression is wrapped with forward slashes (“/”).
- Pattern matches start with backslashes (“\”).
- It is case-sensitive.
- It requires you to match every character of the text you are searching.
- It requires you to learn its special language for matching characters.
The special language of regular expression is how the text you are searching is matched. You need to start the pattern match with a backslash (“\”). After that, you should use a special character to denote what you want to match. For example, a letter or “word character” is matched with “\w” and a number or “digit character” is matched with “\d”.
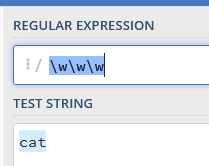
If we want to match all the characters in a string like:
cat
We can use “\w”, as “\w” matches any “word character” or letter, so:
\w\w\w
This matches the three characters “c”, “a”, and “t”. In other words, the first “\w” matches the “c” character; “\w\w” matches “ca”; and “\w\w\w” matches “cat”.
As you can see, “\w” matches any single letter from “a” to “z” and also matches letters from “A” to “Z”. Remember: Regex is case sensitive.
“\w” also matches any number. However, “\w” does NOT match spaces or other special characters, like “-”, “:”, etc. To match other characters, you need to use their special regex symbols or other methods, which we’ll explore here.
Getting Started With Regex
Before we keep going, now is a good time to take a few minutes to find a regex “cheat sheet” you like.
Rapid7 has one you can use: https://docs.rapid7.com/insightops/regular-expression-search/, or you may have a completely different one you prefer. Whatever the case is for you, these guides are helpful in keeping track of all your matching options.
While we’re at it, let’s also find a regex testing tool we can use to practice our regex. https://regex101.com/ is very popular, as it is a tool and cheat sheet in one, although you may find another tool you want to use instead.
InsightIDR supports the version of regex called RE2, so if your parsing tool supports the Golang/RE2 flavor, you might want to select it to practice the specific flavor InsightIDR uses.
To follow along with me, open your preferred tool for testing regex. Enter in some text to match and some regex, and see what happens!
Let’s look at another way to match the string “cat”. You can use literals, which means you just enter the character you want to match:
This means you literally want to match the string “cat”. It matches “cat” and nothing else.
Let’s look at another example. Say I need to match the string:
san-dc01
As we saw earlier, you can use “\w” to match the word characters. To match a number, you can use “\w” or “\d”. “\d” will match any number or “digit”. However, how can you match the “-”?
The dash (“-”) is not a word character, so “\w” does not match it. In this case, we can tell regex we want to match the “-” literally:
\w\w\w-\w\w\d\d
There are other options, as well. The dot or period character (“.”) in regex means to match any single character. This works to parse out the string “san-dc01”, as well:
\w\w\w.\w\w\d\d
While this works, it is tedious typing all these “\w”s. This is where wildcards, sometimes called regex quantifiers, come in handy.
The two most common are:
* match 0 or more characters
+ match 1 or more characters
“\w*” means “match 0 or more word characters”, and “\w+” means “match 1 or more word characters”.
Let’s use these new wildcards to match some text. Say we have these two strings:
cat
san-dc01
I want one regex pattern that will match both strings. Let’s match “cat” first. The regex we used previously:
\w\w\w
matches the string, so you can see that using this wildcard would work, too:
\w+
Now, let’s look at matching “san-dc01”. I can use this:
\w+-\w+
This means “match as many word characters as there are, followed by a dash, and then followed by as many word characters as there are”. However, while this matches “san-dc01”, it does not match “cat”. The string “cat” has no “-” followed by characters.
The regex we added, “-\w+”, only matches a string if the “-” character is part of the string. In addition, “\w+” means “match one or more numbers”. In other words, “\w+” means “match at least one word character up to as many as there are”. As such, we need to use “\w*” here instead to specify that the “dc01” part of the string might not always exist. We also need to use “-*” to specify that the “-” might not always exist in the string we need to match, either.
Therefore, this should work to parse both strings:
\w+-*\w*
By now, you may have noticed something else important about regex: There are usually many different patterns that will match the same text.
Sometimes, I find that people get snooty about their regex, and these people might mock you if they think you could have crafted a shorter pattern or a more efficient one. A pox on their house! Don’t worry about that right now. It’s more important that your regex pattern works than it is that it be short or impressively intricate.
Let’s look at another way to match our strings: You can use a character class for matching.
The character class is defined by using the square brackets “[“ and “]”. It simply means you want regex to match anything included in your defined class.
This is easier than it sounds! Since our strings “cat” and “san-dc01” contain characters that match either “\w” or the literal “-”, our character class is “[\w-]”.
Now, we can use the “+” to specify that our string has one or more characters from the character class:
[\w-]+
Additional Regular Expressions for Log Parsing
Besides “\w” and “\d”, I have a few more regular expressions I want you to pay close attention to. The first one is “\s”, which is how you match whitespaces.
“\s” will match any whitespace character, and “\s+” will match one or more whitespace characters.
Next, remember that the dot (“.”) will match any character. The dot becomes especially powerful when you combine it with the star (“*”). Remember: The star means to match 0 or more characters. Therefore, the “dot star” (“.*”) will match any characters as many times as they appear, including matching nothing. In other words, “.*” matches anything.
Finally, let’s look at special uses of the circumflex character, which is often just called the hat (“^”).
The hat has two completely different uses, which should not be confused. First, when used by itself, the hat in regex designates where the beginning of the line starts. For example, “^\w+” means that the line must start with a word.
The second use of the hat is when it appears in a character class. If you use the hat character when defining a character class, it means “everything except” as in “match everything except these characters”. In other words, “[\d]+” would match any digit character, while “[^\d]+” means to do the opposite or match everything except for any digit character!
Log Parsing Examples
Let’s go back to where we started, trying to parse out the msg field from our logs:
May 10 12:43:12 SECRETSERVERHOST CEF:0|Thycotic Software|Secret Server|10.9.000002|500|System Log|7|msg=The server could not be contacted. rt=May 10 2021 12:43:12
May 10 12:43:41 SECRETSERVERHOST CEF:0|Thycotic Software|Secret Server|10.9.000002|500|System Log|7|msg=The RPC Server is unavailable. rt=May 10 2021 12:43:41
Have you copied and pasted these log lines into your regex tester? If not, go ahead and do so now.
We need to parse a literal string “msg=”. These literals in log lines are often the “key” part of a key-value pair and are sometimes called anchors instead of literals, since they are the same in every log line. To parse them, you would usually specify the literal string to match on.
Next, we need to read the value that follows. You have a few different approaches you can use here. A common way to parse the value is to read everything that follows until the next literal or anchor. Remember: There are many ways to do this, but your regex might look like this:
msg=.*rt=
By the way, if you are familiar with regex, you know that the greedy “*” creates inefficient parsing rules, but let’s not worry too much about that right now. The skinny on this, however, is that you should never use the dot star (“.*”) for parsing rules. It is useful for searches and trying to figure out log structure, though.
Another way to read the value is to use a character class:
msg=[\w\s\.]+rt=
Let’s break the character class down to determine exactly what is specified. “\w” means match any word character. “\s” means to match any space. We also need to match a literal period, since that appears in the msg value, but the period or dot has a special meaning in regex. When characters have special meaning in regex, like the slashes, brackets, dot, etc, they need to be “escaped”, which you do by putting a backslash (“\”) in front of them. Therefore, to match the period, we need to use “\.” in the character class.
Remember: Defining a character class means you want to match any character defined in the class, and the “+” at the end of the class means to “match one or more of these characters”. In that case, “[\w\s\.]+” means “match any word character, any space, or a period as many times as it occurs”. The matching will stop when the next character in the sequence is not a word character, a space, or a period OR when the next part of the regex is matched. The next part of the regex is the literal string “rt=”, so the regex will extract the “[\w\s\.]+” characters until it gets to “rt=”.
Finally, there is just one more regex syntax that is helpful to understand when using regex with InsightIDR, and that is the use of capture groups. A capture group is how you define key names in regex. Capture groups are actually much more than this, but let’s narrow our focus to just what we need to know for using them with InsightIDR. To specify a named capture group for our purposes, use this syntax:
(?P<keyname>putyourregexhere)
The regex you put into the capture group is what is used to read the value that is going to match the “keyname”. Let’s see how this works with our logs.
Say we have some logs in key-value pair (KVP) format, and we want to both define and parse out the “msg” key. We know this regex works to match our logs: “msg=[\w\s\.]+rt=”. Now, we need to take this one step further and define the “msg” key and its values. We can do that with a named capture group:
msg=(?P<msg>[\w\s\.]+)rt
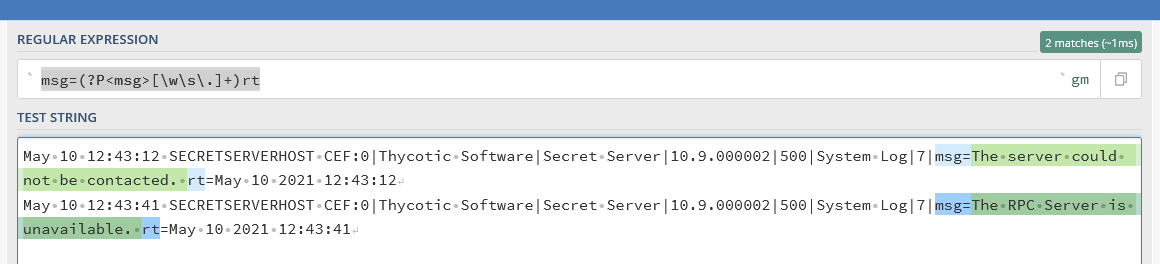
Let’s break this down. We want to read in the literal string “msg=” and then place everything after it into a capture group, stopping at the literal string “rt=”. The capture group defines the key, which you can also think of as a “field name”, as “msg”: “(?P<msg>”.
If we wanted to parse the field name as something else, we could specify that in between the “<>”. For example, if we wanted the field name to be “message” instead of “msg”, we would use: “(?P<message>”.
The regex that follows is what we want to read for the value part of our key-value pair. In other words, it is what we want to extract for the “msg”. We already know from our previous work that the character class “[\w\s\.]” matches our logs, so that’s what is used for this regex.
In this blog, we explored the regex syntax we need for InsightIDR and used a generic tool to test our regular expressions. In the next blog, we’ll use what we covered here to write our own parsing rules in InsightIDR using the Custom Parsing Tool in Regex Editor mode.