
By Dr. Mike Cohen and Carlos Canto
Rapid7 is very excited to announce that version 0.7.2 of Velociraptor is now fully available for download.
In this post we’ll discuss some of the interesting new features.
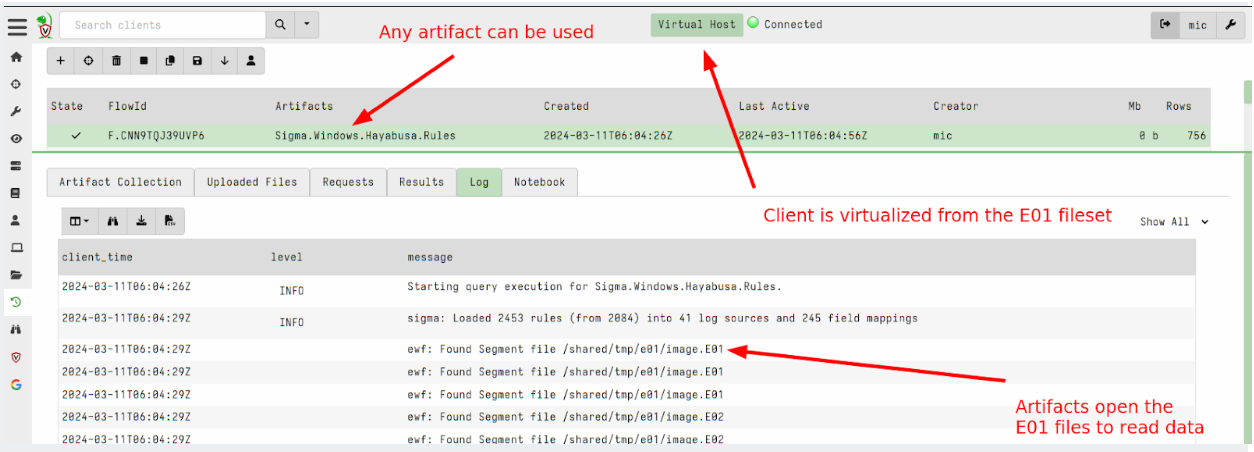
EWF Support
Velociraptor has introduced the ability to analyze dead disk images in the past. Although we don’t need to analyze disk images very often, it comes up occasionally.
Previously, Velociraptor only supported analysis of DD images (AKA “Raw images”). Most people use standard acquisition software to acquire images, which uses the common EWF format to compress them.
In this 0.7.2 release, Velociraptor supports EWF (AKA E01) format using the ewf accessor. This allows Velociraptor to analyze E01 image sets.
To analyze dead disk images use the following steps:
- Create a remapping configuration that maps the disk accessors into the E01 image. This automatically diverts VQL functions that look at the filesystem into the image instead of using the host’s filesystem. In this release you can just point the --add_windows_disk option to the first disk of the EWF disk set (the other parts are expected to be in the same directory and will be automatically loaded).
The following creates a remapping file by recognizing the windows partition in the disk image.
$ velociraptor-v0.72-rc1-linux-amd64 deaddisk
--add_windows_disk=/tmp/e01/image.E01 /tmp/remapping.yaml -v
2. Next we launch a client with the remapping file. This causes any VQL queries that access the filesystem to come from the image instead of the host. Other than that, the client looks like a regular client and will connect to the Velociraptor server just like any other client. To ensure that this client is unique you can override the writeback location (where the client id is stored) to a new file.
$ velociraptor-v0.72-rc1-linux-amd64 --remap /tmp/remapping.yaml
--config ~/client.config.yaml client -v
--config.client-writeback-linux=/tmp/remapping.writeback.yaml
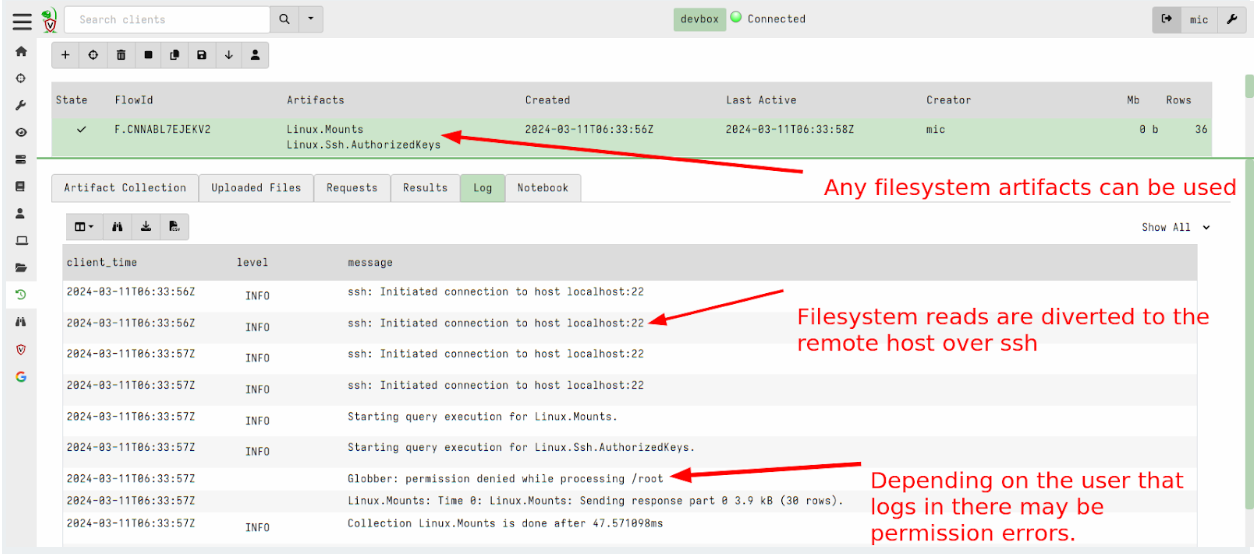
Allow remapping clients to use SSH accessor
Sometimes we can’t deploy the Velociraptor client on a remote system. (For example, it might be an edge device like an embedded Linux system or it may not be directly supported by Velociraptor.)
In version 0.7.1, Velociraptor introduced the ssh accessor which allows VQL queries to use a remote ssh connection to access remote files.
This release added the ability to apply remapping in a similar way to the dead disk image method above to run a Virtual Client which connects to the remote system via SSH and emulates filesystem access over the sftp protocol.
To use this feature you can write a remapping file that maps the ssh accessor instead of the file and auto accessors:
remappings:
type: permissions
permissions:- COLLECT_CLIENT
- FILESYSTEM_READ
- READ_RESULTS
- MACHINE_STATE
type: impersonation
os: linux
hostname: RemoteSSHtype: mount
scope: |
LET SSH_CONFIG <= dict(hostname='localhost:22',
username='test',
private_key=read_file(filename='/home/test/.ssh/id_rsa'))from:
accessor: ssh"on":
accessor: auto
path_type: linuxtype: mount
scope: |
LET SSH_CONFIG <= dict(hostname='localhost:22',
username='test',
private_key=read_file(filename='/home/test/.ssh/id_rsa'))from:
accessor: ssh"on":
accessor: file
path_type: linux
Now you can start a client with this remapping file to virtualize access to the remote system via SSH.
$ velociraptor-v0.72-rc1-linux-amd64 --remap /tmp/remap_ssh.yaml
--config client.config.yaml client -v
--config.client-writeback-linux=/tmp/remapping.writeback_ssh.yaml
--config.client-local-buffer-disk-size=0
GUI Changes
The GUI has been significantly improved in this release.
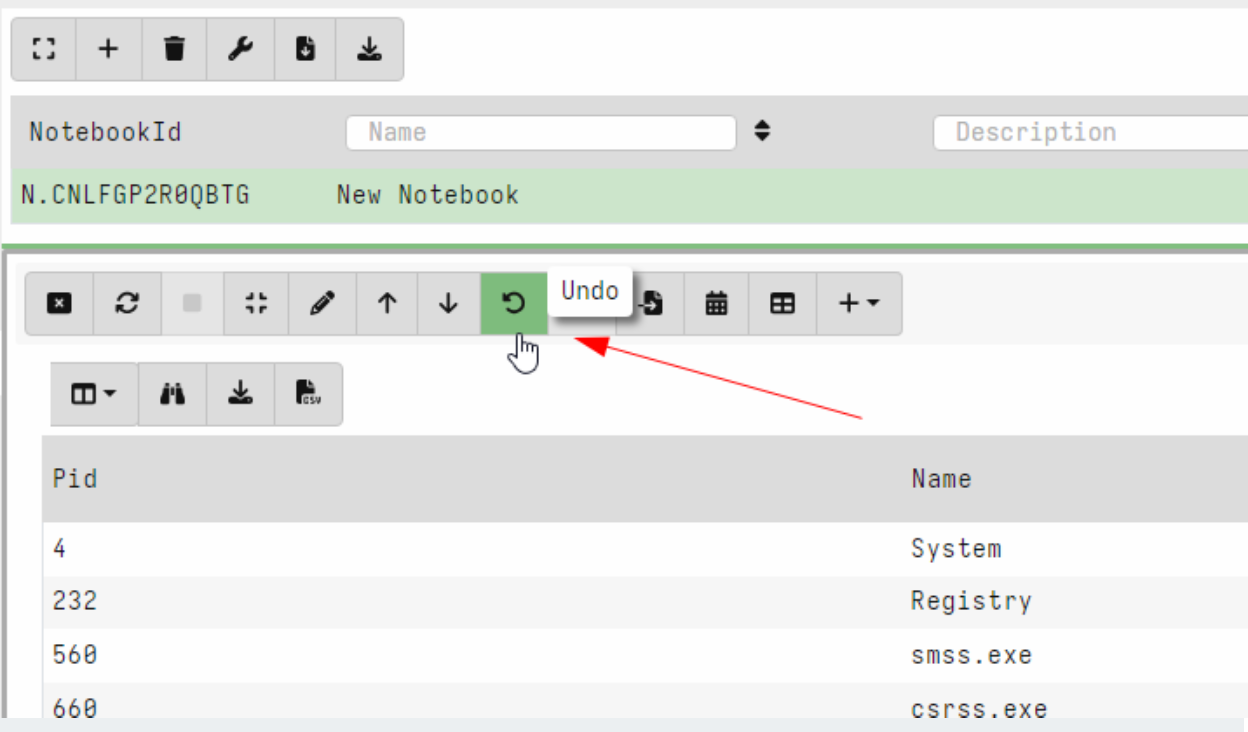
Undo/Redo for notebook cells
Velociraptor offers an easy way to experiment and explore data with VQL queries in the notebook interface. Naturally, exploring the data requires going back and forth between different VQL queries.
In this release, Velociraptor keeps several versions of each VQL cell (by default 5) so as users explore different queries they can easily undo and redo queries. This makes exploring data much quicker as you can go back to a previous version instantly.
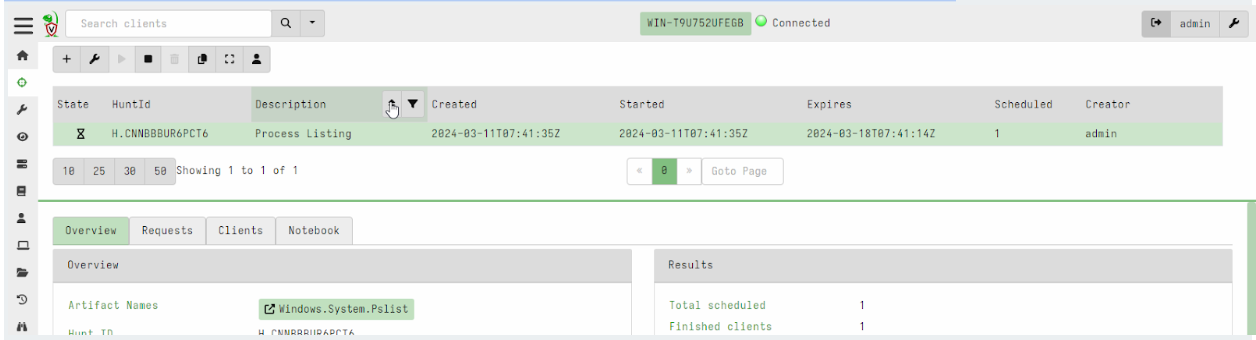
Hunt view GUI is now paged
Previously, hunts were presented in a table with limited size. In this release, the hunt table is paged and searchable/sortable. This brings the hunts table into line with the other tables in the interface and allows an unlimited number of hunts to be viewable in the system.
Secret Management
Many Velociraptor plugins require secrets to operate. For example, the ssh accessor requires a private key or password to log into the remote system. Similarly the s3 or smb accessors require credentials to upload to the remote file servers. Many connections made over the http_client() plugin require authorization – for example an API key to send Slack messages or query remote services like Virus Total.
Previously, plugins that required credentials needed those credentials to be passed as arguments to the plugin. For example, the upload_s3() plugin requires AWS S3 credentials to be passed in as parameters.
This poses a problem for the Velociraptor artifact writer: how do you safely provide the credentials to the VQL query in a way that does not expose them to every user of the Velociraptor GUI? If the credentials are passed as parameters to the artifact then they are visible in the query logs and request, etc.
This release introduces Secrets as a first class concept within VQL. A Secret is a specific data object (key/value pairs) given a name which is used to configure credentials for certain plugins:
- A Secret has a name which we use to refer to it in plugins.
- Secrets have a type to ensure their data makes sense to the intended plugin. For example a secret needs certain fields for consumption by the s3 accessor or the http_client() plugin.
- Secrets are shared with certain users (or are public). This controls who can use the secret within the GUI.
- The GUI is careful to not allow VQL to read the secrets directly. The secrets are used by the VQL plugins internally and are not exposed to VQL users (like notebooks or artifacts).
Let’s work through an example of how Secrets can be managed within Velociraptor. In this example we store credentials for the ssh accessor to allow users to glob() a remote filesystem within the notebook.
First we will select manage server secrets from the welcome page.
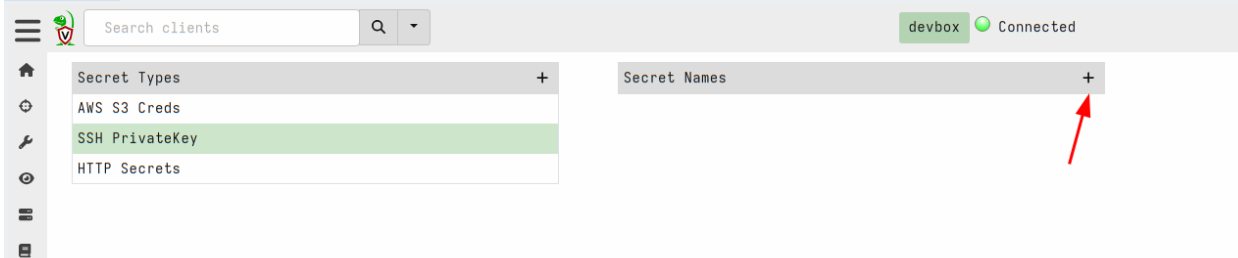
Next we will choose the SSH PrivateKey secret type and add a new secret.
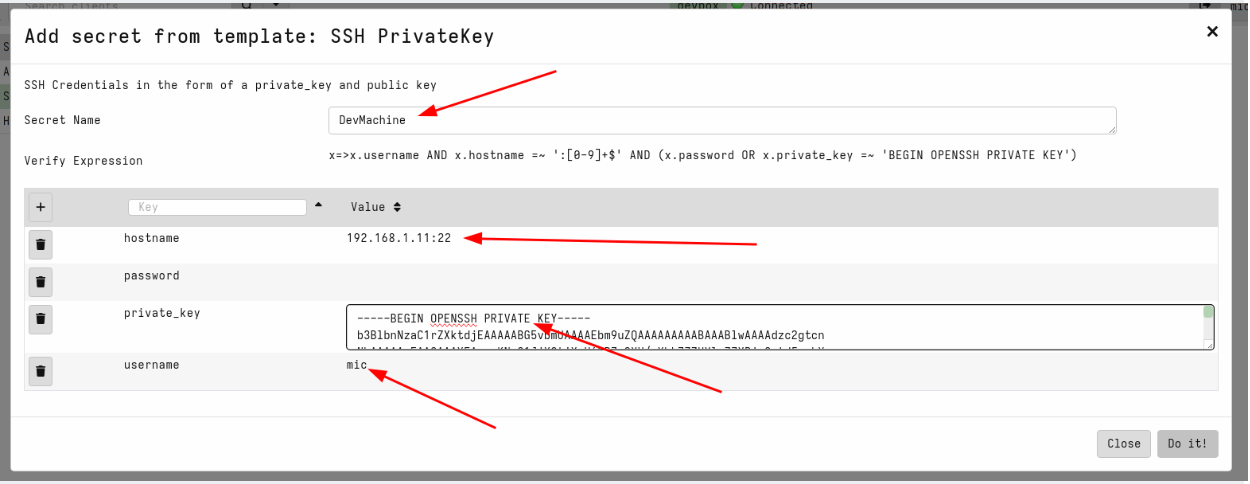
This will use the secret template that corresponds to the SSH private keys. The acceptable fields are shown in the GUI and a validation VQL condition is also shown for the GUI to ensure that the secret is properly populated. We will name the secret DevMachine to remind us that this secret allows access to our development system. Note that the hostname requires both the IP address (or dns name) and the port.
Next we will share the secrets with some GUI users
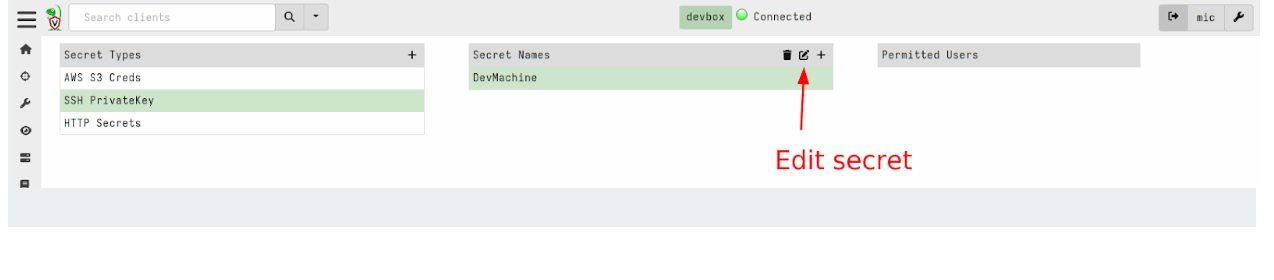
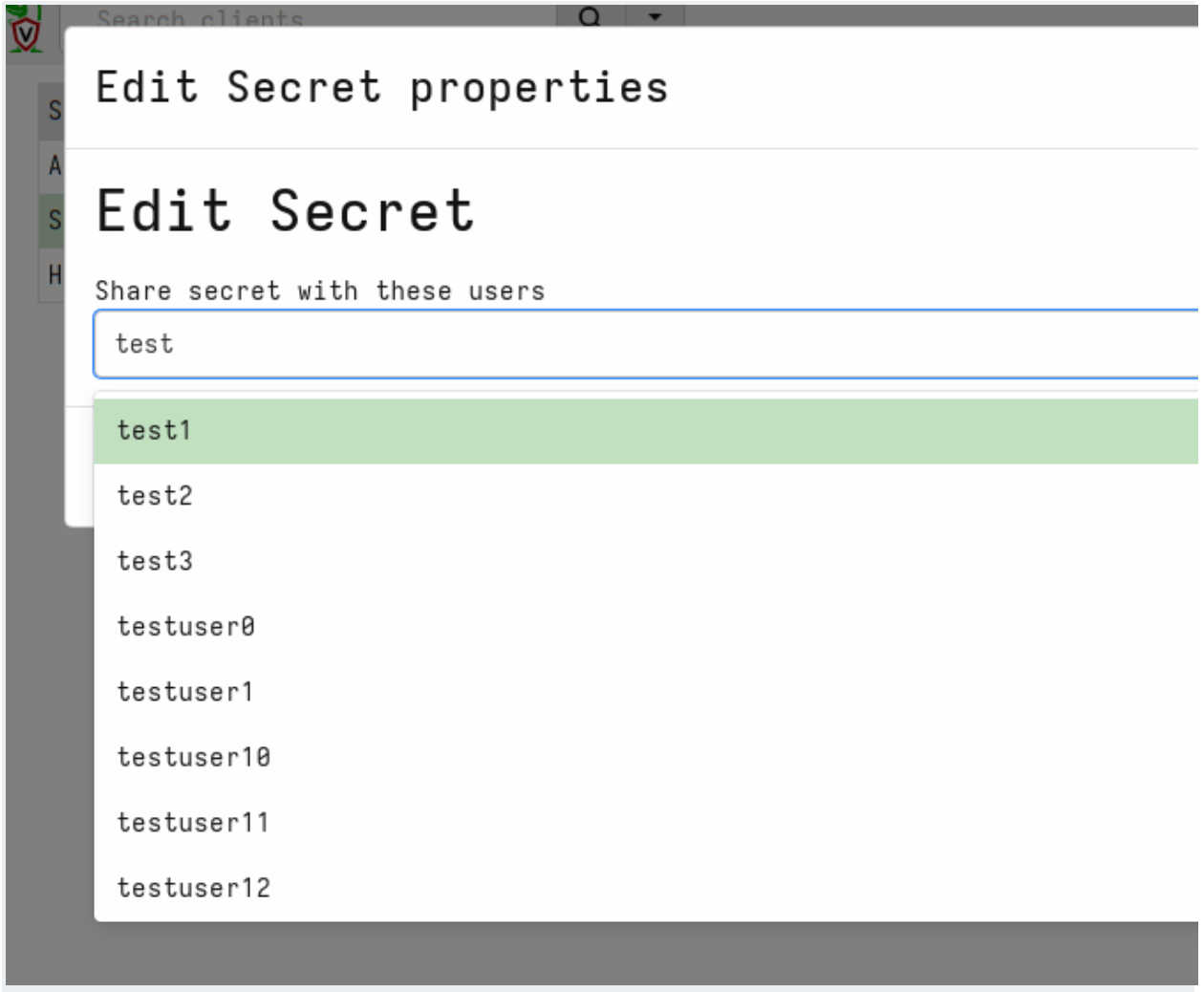
We can view the list of users that are able to use the secret within the GUI

Now we can use the new secret by simply referring to it by name:
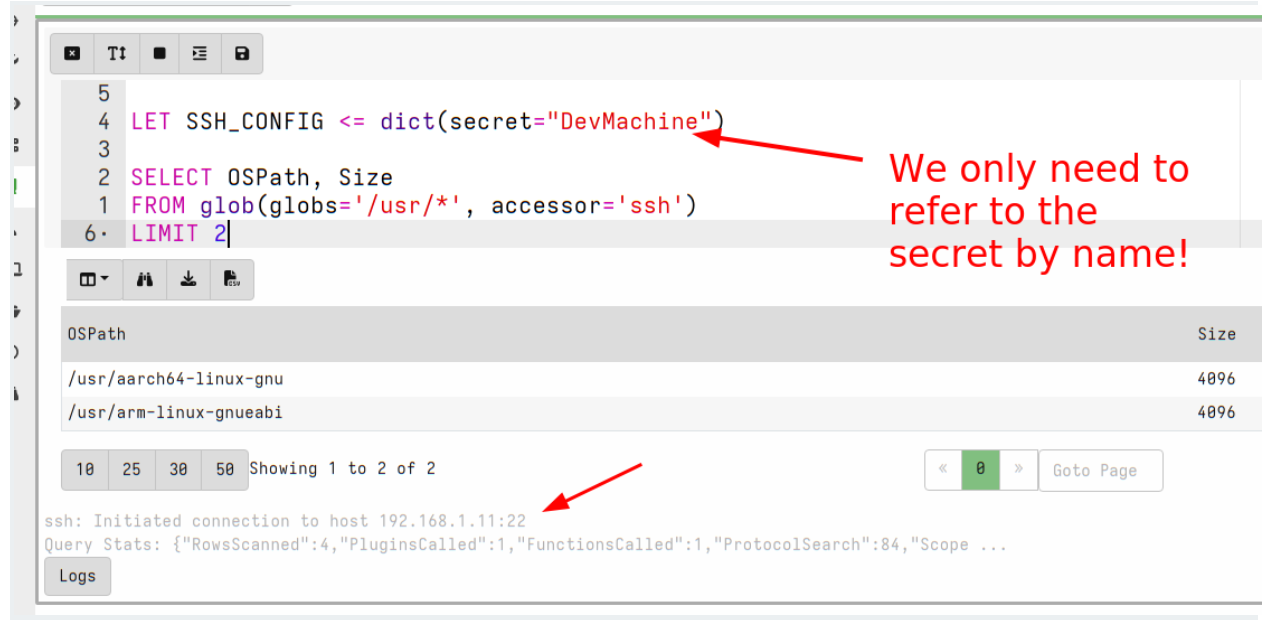
Not only is this more secure but it is also more convenient since we don’t need to remember the details of each secret to be able to use it. For example, the http_client() plugin will fill the URL field, headers, cookies etc directly from the secret without us needing to bother with the details.
WARNING: Although secrets are designed to control access to the raw credential by preventing users from directly accessing the secrets' contents, those secrets are still written to disk. This means that GUI users with direct filesystem access can simply read the secrets from the disk.
We recommend not granting untrusted users elevated server permissions like EXECVE or Filesystem Read as it can bypass the security measures placed on secrets.
Server improvements
Implemented Websocket based communication mechanism
One of the most important differences between Velociraptor and some older remote DFIR frameworks such as GRR is the fact that Velociraptor maintains a constant, low latency connection to the server. This allows Velociraptor clients to respond immediately without needing to wait for polling on the server.
In order to enhance compatibility between multiple network configurations like MITM proxies, transparent proxies etc., Velociraptor has stuck to simple HTTP based communications protocols. To keep a constant connection, Velociraptor uses the long poll method, keeping HTTP POST operations open for a long time.
However as the Internet evolves and newer protocols become commonly used by major sites, the older HTTP based communication method has proven more difficult to use. For example, we found that certain layer 7 load balancers interfere with the long poll method by introducing buffering to the connection. This severely degrades communications between client and server (Velociraptor falls back to a polling method in this case).
On the other hand, modern protocols are more widely used, so we found that modern load balancers and proxies already support standard low latency communications protocols such as Web Sockets.
In the 0.7.2 release, Velociraptor introduces support for websockets as a communications protocol. The websocket protocol is designed for low latency and low overhead continuous communications methods between clients and server (and is already used by most major social media platforms, for example). Therefore, this new method should be better supported by network infrastructure as well as being more efficient.
To use the new websocket protocol, simply set the client’s server URL to have wss:// scheme:
Client:
server_urls:
- wss://velociraptor.example.com:8000/
- https://velociraptor.example.com:8000/
You can use both https and wss URLs at the same time, Velociraptor will switch from one to the other scheme if one becomes unavailable.
Dynamic DNS providers
Velociraptor has the capability to adjust DNS records by itself (AKA Dynamic DNS). This saves users the hassle of managing a dedicated dynamic DNS service such as ddclient).
Traditionally we used Google Domains as our default Dynamic DNS provider, but Google has decided to shut down this service abruptly forcing us to switch to alternative providers.
The 0.7.2 release has now switched to CloudFlare as our default preferred Dynamic DNS provider. We also added noip.com as a second option.
Setting up CloudFlare as your preferred dynamic DNS provider requires the following steps:
- Sign into CloudFlare and buy a domain name.
- Go to https://dash.cloudflare.com/profile/api-tokens to generate an API token. Select Edit Zone DNS in the API Token templates.
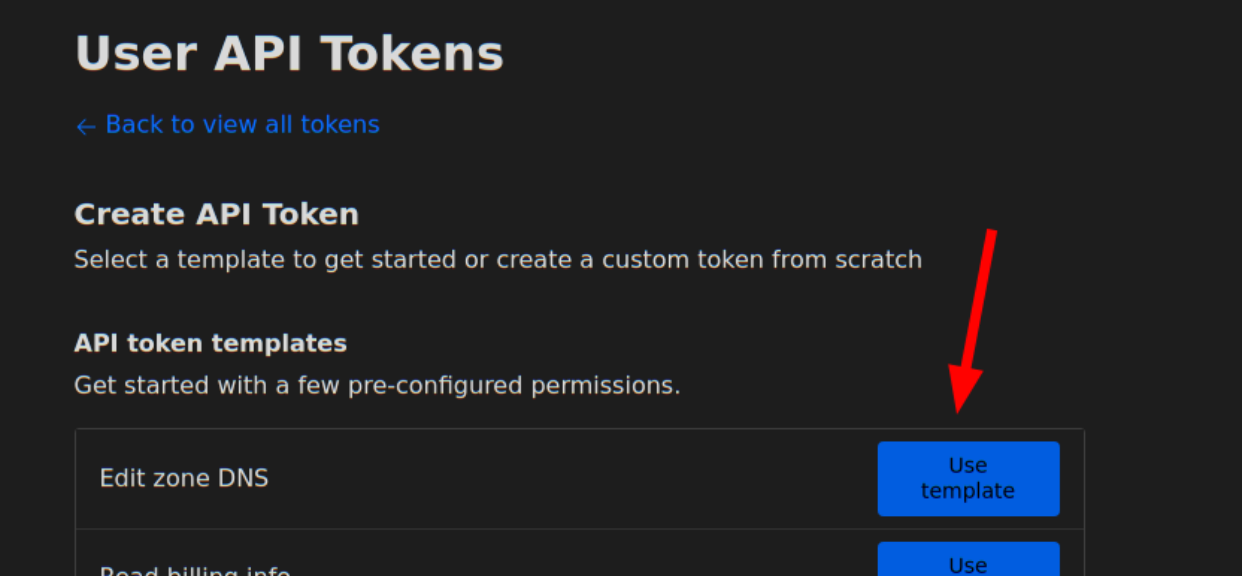
You will need to require the “Edit” permission on Zone DNS and include the specific zone name you want to manage. The zone name is the domain you purchased, e.g. “example.com”. You will be able to set the hostname under that domain, e.g. “velociraptor.example.com”.
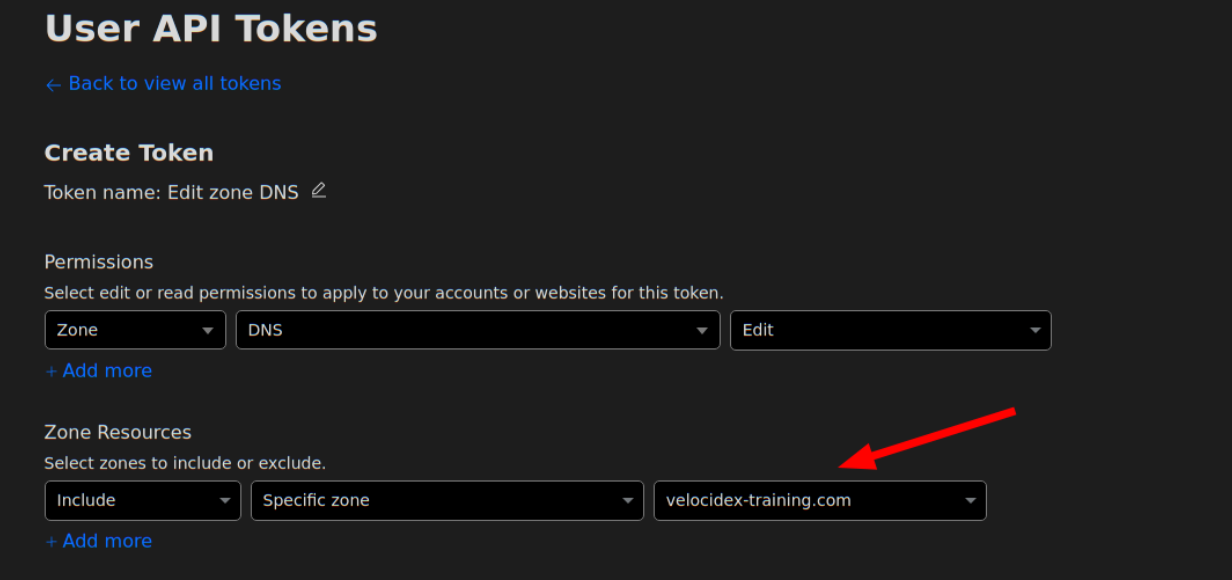
Using this information you can now create the dyndns configuration:
Frontend:
....
dyn_dns:
type: cloudflare
api_token: XXXYYYZZZ
zone_name: example.com
Make sure the Frontend.Hostname field is set to the correct hostname to update - for example
Frontend:
hostname: velociraptor.example.com
This is the hostname that will be updated.
Enhanced proxy support
Velociraptor is often deployed into complex enterprise networks. Such networks are often locked down with complicated controls (such as MITM inspection proxies or automated proxy configurations) which Velociraptor needs to support.
Velociraptor already supports MITM proxies but previously had inflexible proxy configuration. The proxy could be set or unset but there was no finer grained control over which proxy to choose for different URLs. This makes it difficult to deploy on changing network topologies (such as roaming use).
The 0.7.2 release introduces more complex proxy condition capabilities. It is now possible to specify which proxy to use for which URL based on a set of regular expressions:
Client:
proxy_config:
http: http://192.168.1.1:3128/
proxy_url_regexp:
"^https://www.google.com/": ""
"^https://.+example.com": "https://proxy.example.com:3128/"
The above configuration means to:
- By default connect to http://192.168.1.1:3128/ for all URLs (including https)
- Except for www.google.com which will be connected to directly.
- Any URLs in the example.com domain will be forwarded through https://proxy.example.com:3128
This proxy configuration can apply to the Client section or the Frontend section to control the server’s configuration.
Additionally, Velociraptor now supports a Proxy Auto Configuration (PAC) file. If a PAC file is specified, then the other configuration directives are ignored and all configuration comes from the PAC file. The PAC file can also be read from disk using the file:// URL scheme, or even provided within the configuration file using a data: URL.
Client:
proxy_config:
pac: http://www.example.com/wpad.dat
Note that the PAC file must obviously be accessible without a proxy.
Other notable features
Other interesting improvements include:
Process memory access on MacOS
On MacOS we can now use proc_yara() to scan process memory. This should work providing your TCT profile grants the get-task-allow, proc_info-allow and task_for_pid-allow entitlements. For example the following plist is needed at a minimum:
com.apple.springboard.debugapplicationsget-task-allowproc_info-allowtask_for_pid-allowMultipart uploaders to http_client()
Sometimes servers require uploaded files to be encoded using the mutipart/form method. Previously it was possible to upload files using the http_client() plugin by constructing the relevant request in pure VQL string building operations.
However this approach is limited by available memory and is not suitable for larger files. It is also non-intuitive for users.
This release adds the files parameter to the http_client() plugin. This simplifies uploading multiple files and automatically streams those files without memory buffering - allowing very large files to be uploaded this way.
For example:
SELECT *
FROM http_client(
url='http://localhost:8002/test/',
method='POST',
files=dict(file='file.txt', key='file', path='/etc/passwd', accessor="file")
Here the files can be an array of dicts with the following fields:
- file: The name of the file that will be stored on the server
- key: The name of the form element that will receive the file
- path: This is an OSPath object that we open and stream into the form.
- accessor: Any accessor required for the path.
Yara plugin can now accept compiled rules
The yara() plugin was upgraded to use Yara Version 4.5.0 as well as support compiled yara rules. You can compile yara rules with the yarac compiler to produce a binary rule file. Simply pass the compiled binary data to the yara() plugin’s rules parameter.
WARNING: We do not recommend using compiled yara rules because of their practical limitations:
- The compiled rules are not portable and must be used on exactly the same version of the yara library as the compiler that created them (Currently 4.5.0)
- Compiled yara rules are much larger than the text rules.
Compiled yara rules pose no benefit over text based rules, except perhaps being more complex to decompile. This is primarily the reason to use compiled rules - to try to hide the rules (e.g. from commercial reasons).
Conclusions
There are many more new features and bug fixes in the 0.7.2 release. If you’re interested in any of these new features, why not take Velociraptor for a spin by downloading it from our release page? It’s available for free on GitHub under an open-source license.
As always, please file bugs on the GitHub issue tracker or submit questions to our mailing list by emailing [email protected]. You can also chat with us directly on our Discord server.
Learn more about Velociraptor by visiting any of our web and social media channels below:




