

“The price of reliability is the pursuit of the utmost simplicity” – C.A.R Hoare
Rather than doing another all-out performance post, I’ll look at some aspects of asynchronous I/O today instead: what it is at a high level, what it isn’t and why you would use it.
There aren’t many aspects of programming today that are as saturated with buzzwords and misinformation as asynchronous IO and some of the frameworks which build on top of this. If you work with server code which has to handle a nontrivial number of connections at the same time you’ve probably overheard people saying things like, “if this were nonblocking it’d be much faster” or “we’d get much better throughput with node.js”, with ensuing nods and stroking of beards. Even after you’ve taken the plunge with node, people will implore you to “not block the event-loop!”- but the more JS meetups you go to, the less you can figure out why…
“JS is fast these days, right?”
Node.js has captured a huge chunk of developer mindshare because of its use of JavaScript to expose a nonblocking, event-driven API. Using Google’s V8 JS interpreter, code written for node can sometimes be seen to come within an order of magnitude of the sequential speed of comparable C-based routines. That’s pretty impressive for a dynamic language. If straight speed were the only concern of a web-scale application, I could wrap this post up here. Things aren’t that simple though; if you have node on your résumé, you should be able to answer the less intuitive and more interesting question: “when wouldn’t you use it?”.
Giants’ shoulders
In addition to V8, node builds on many of the facilities that modern OS kernels have added in the last decade to allow developers solve the C10K problem. There are a couple of challenges associated with handling huge numbers of customers’ connections concurrently. I’ll try to minimize the diagrams and system calls here, but skimming the appendix of K&R wouldn’t do any harm. The big trick with past APIs has been figuring out which clients are actually doing something (i.e. have sent data or disconnected) and which ones are just idling. Historically developers on UNIXy systems have relied on a couple of system calls, namely select() and poll() to do this kind of connection multiplexing. In typical [vastly simplified!] usage, they work like this:
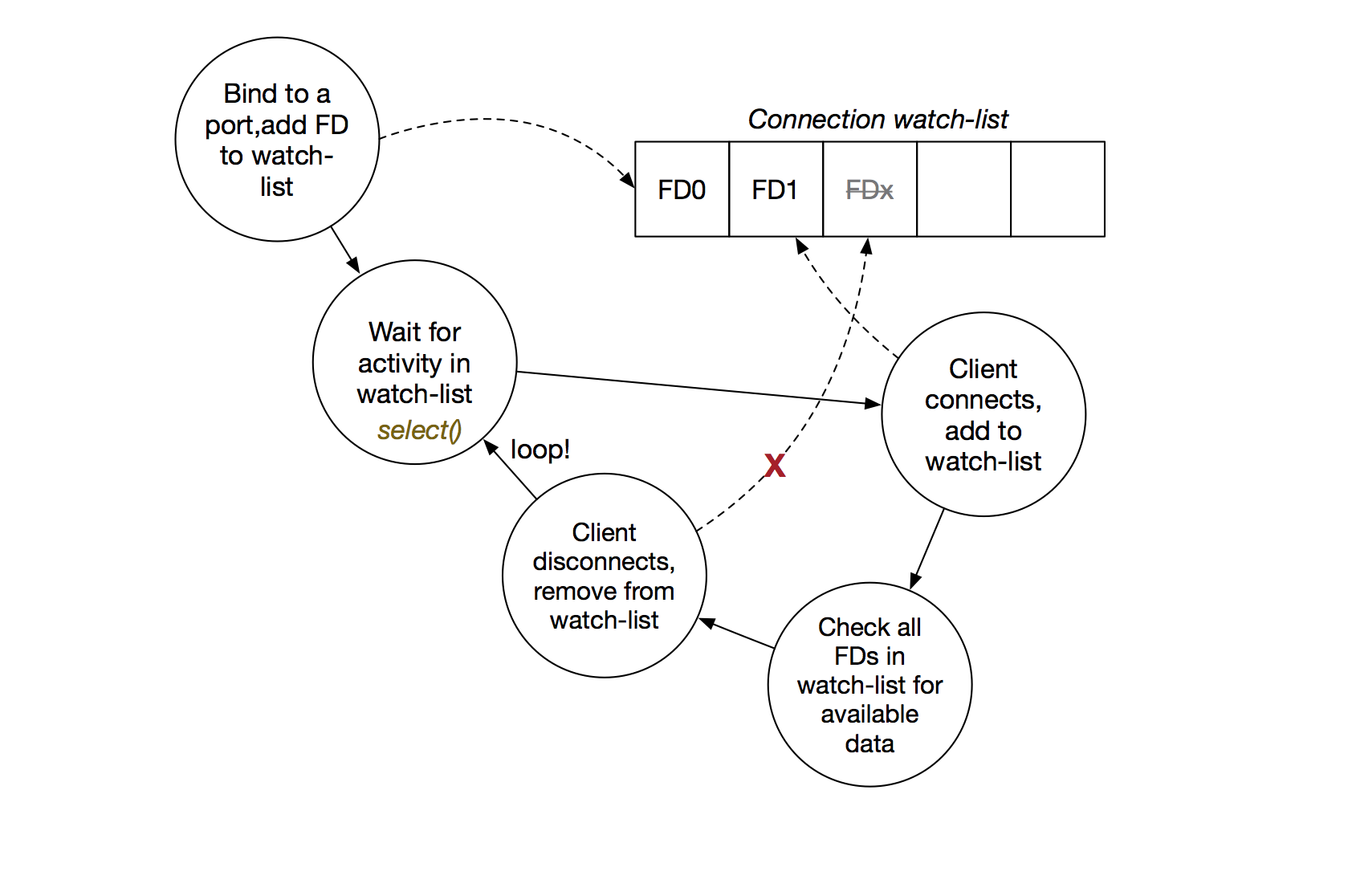
After listening on a port, the server sits in a loop, beginning each iteration with a call to select() or poll(), passing in an array of file descriptors it is interested in (initially the only FD it knows about will be the one referring to the bound port which accepts incoming connections). When a client connects, the application will commonly run through the array (I called it a watch-list in the diagram, but you get the idea) until it finds an empty slot to store the FD. After it’s done that, it has to iterate through the watch-list again and attempt to read from each client, removing it from the watch-list if it hits an EOF during the read() call. That works, but presents a few problems when the number of concurrent connections becomes huge:
- If you’re using select(), the size of the watch-list can be at most FD_SETSIZE (which is 1024 on Linux)
- Adding new clients to the list takes O(n) time in the worst-case [hint: it’s a list!]
- You have to iterate over every single client to discover any events (data to be read, clients who have disconnected), which again is O(n)
If you’re using poll(), point 3 may put a very noticeable cap on the maximum concurrent connections that can be serviced because the set of watched connections can now be very large. On top of that, because this watch-list lives in user space, each iteration incurs at least one context-switch (e.g. a read call) which adds another small constant overhead to the receive loop.
As C10K has morphed into C10M+, system designers have had to come up with facilities in OS kernels to handle these volumes of open sockets without incurring a linear slowdown in application performance. To compliment select and poll, linux added the epoll family of calls in the early 2000s. BSD developed a superficially similar API called kqueue and Solaris’ /dev/poll device predates the other two, but since we use Linux in production, let’s focus on that.
Event loops and reactors
Epoll effectively inverts the watch-list model so it lives on a special epoll file descriptor inside the kernel. When a client connects, you add its file descriptor to the watch-list via the epoll_ctl() command [internally, epoll FDs are stored in a red-black tree for fast updates]. Instead of blocking via select() at the start of our loop, our server calls epoll_wait(), and sleeps until some events come through. When a socket in the interest set undergoes a state change (new client, new data, e.t.c) it piles the event onto the epoll FD our loop is waiting on, waking up the server process. The structure of our server now looks something like this:
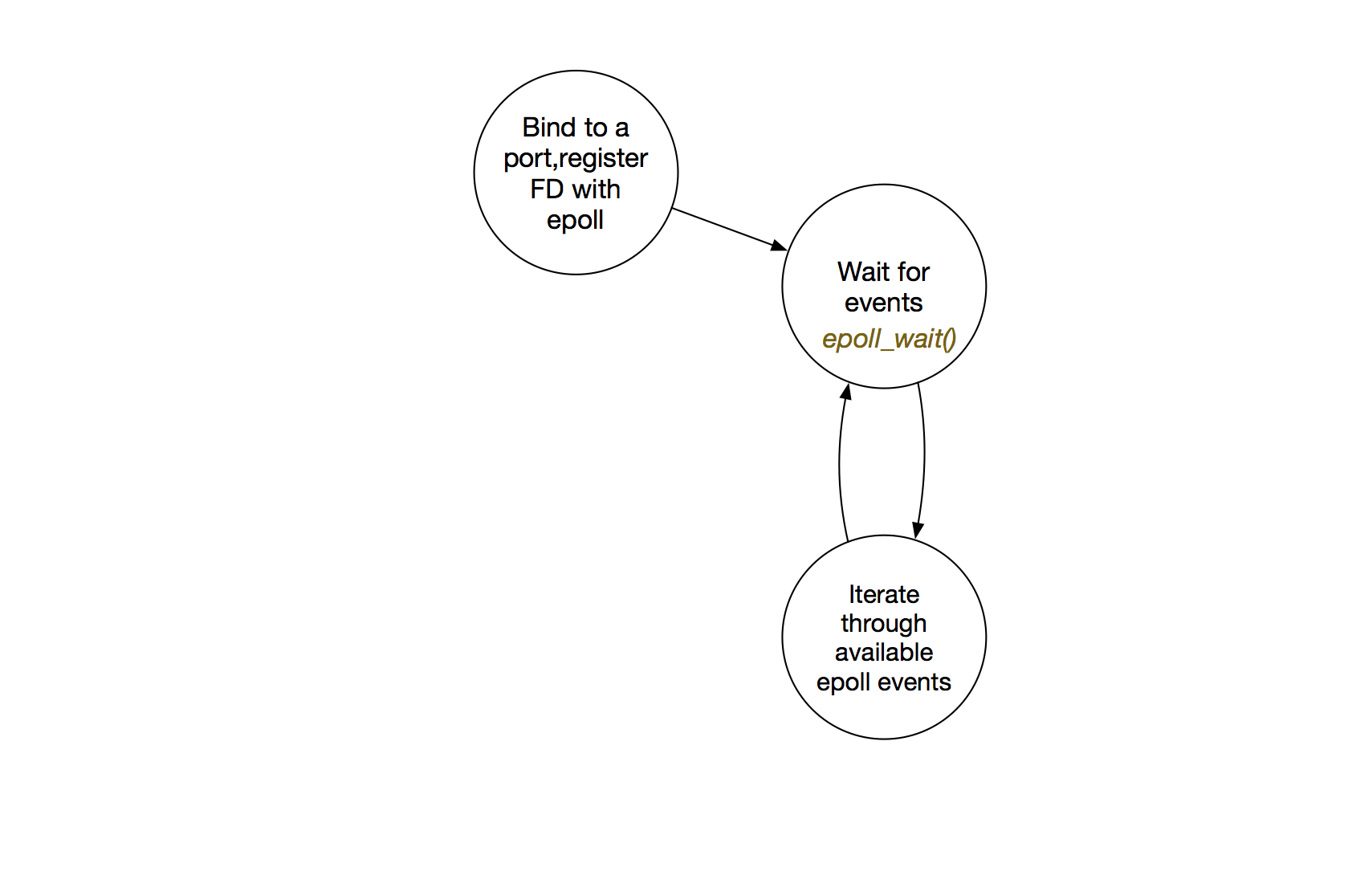
This is much nicer- our process only gets notified when events actually happen, which restricts the file descriptors we have to iterate over- we don’t have to do linear scans through a watch list. Used in tandem with non-blocking I/O operations, the benchmarks are compelling. What exactly do we do with those events when we’re iterating through them? We perform standard UNIX file read and write operations depending on the nature of the event, but there’s a complication: a plain read() from a socket like this:
// ‘buffer’ is a char array, socket is our file descriptor read(socket, buffer, sizeof buffer);
is going to block until complete- in practice this’ll happen at every iteration in our loop. That still puts a big limit on the scalability of our solution. To fix this we need to put each client connection into non-blocking mode by using fcntl() to set the O_NONBLOCK flag [error-handling omitted for brevity]:
// get the current flags on the socket
int flags = fcntl(socket, F_GETFL, 0);
// add O_NONBLOCK flag
fcntl(socket, F_SETFL, flags |= O_NONBLOCK);
With our client I/O calls returning control to the caller straight away, go ahead and deal with the next epoll event in the same manner- no waiting. With that in mind, let’s take another look at how we iterate through and react to epoll events:
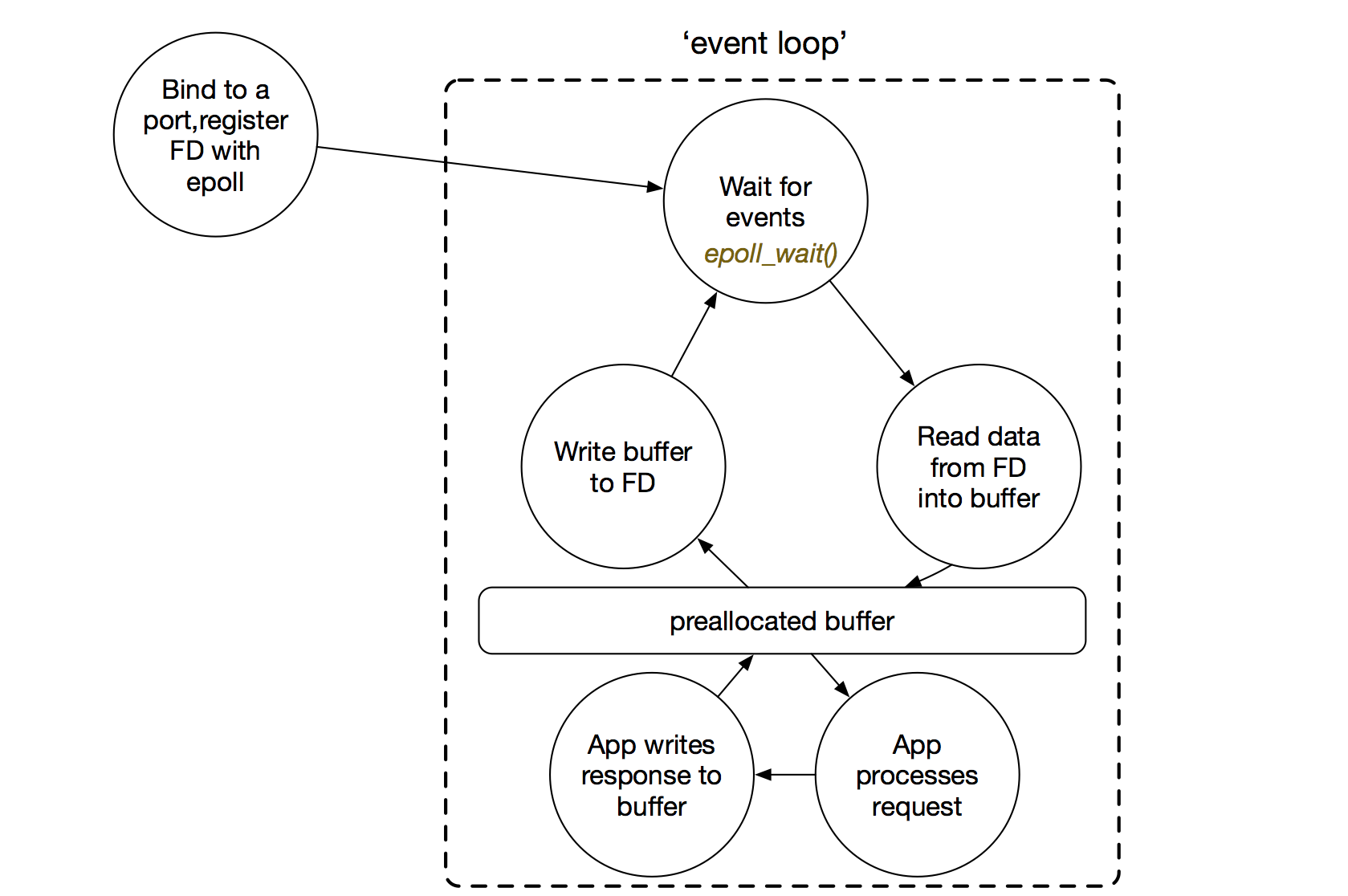
This design pattern is sometimes referred to as a ‘reactor’ and underpins many event-driven network libraries such as Netty, Twisted, Eventmachine and of course node. In our setup, events are picked up solely from epoll and ‘dispatched’ on the same thread within each loop iteration to our request handler ‘app’. Why is our simplistic reactor design good?
- It’s single-threaded meaning: - no inter-thread context-switching overhead
- implementation is typically simpler
- A single preallocated memory buffer can be reused for reads and writes- depending if you’re writing in a language with automatic memory management, this eliminates either: - intermediate malloc() calls, or
- a garbage collector managing lots of young-generation byte arrays
There’s something to be said for simplicity; IO multiplexing in node.js works in a very similar manner, partly because the V8 engine doesn’t allow hosted code to run concurrently. Let’s just be clear there: node doesn’t run any of your application code in parallel. If a single-threaded reactor is such a great way of handling huge numbers of connections, let’s circle back to the original question: why wouldn’t you use it?
You may recall a famous-for-15-minutes blog post about 5 years ago which demoed a toy node.js application for computing Fibonacci numbers. You could write a pure recursive implementation of a function to compute fib(n) in javascript like this:
function fib(n) {
if (n <= 1) {
return n;
}
return fib(n-1) + fib(n-2);
}
It’s grossly inefficient and if you’ve heard of dynamic programming you should be able to derive a constant-space, linear-time solution easily enough, but it illustrates that sometimes your app will be unexpectedly slow: maybe a routine which scavenged stale session data turns out to take O(n2) time, maybe a third-party DB client now blocks when updating something- it happens.
If stuff like this happens inside a server with a worker/boss threading model, you can absorb heavily CPU-bound operations like calculating fib(40) but in node, every other event gets backed up while the loop crunches the result, one request at a time. Not great. On my machine, running the following node.js service:
var http = require('http');
http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end(fib(40).toString());
}).listen(8080, “127.0.0.1");
…and hitting it extremely modestly with ApacheBench (10 requests, 1 connection, keep-alive enabled) gave me these less than stellar results:
Requests per second: 0.77 [#/sec] (mean)
Time per request: 1299.449 [ms] (mean)
Other languages like Java and C++ can use a hybrid worker / boss model to dispatch resource-constrained work to a background thread (Netty and Twisted let you do this, for example).
Why wouldn’t I use node again?
Alright, rubbishing node.js by hammering a fib function is old news, but hopefully by going from epoll all the way up to the application code you can hopefully get a better sense of why people pick up on it, and also where it shines. The main point here is that the single threaded nature of the node runtime forces developers to participate in the design by making their own server-side code entirely non-blocking. Not only is that sometimes hard to do but it tightly couples the internals of your application to a given threading-model. With single-threaded event loops, the price of reliability is not just simplicity but also incidental complexity.




