
System monitoring and troubleshooting can be a time-consuming and frustrating activity. It’s not unusual for IT folks to spend hours finding and fixing a problem that could have been resolved in 10 minutes had better troubleshooting tools and processes been in place.
Improving IT troubleshooting and monitoring doesn’t need to be an expensive undertaking. Many times it’s just a matter of implementing a few company-wide guidelines. Let’s look at six best practices that will make troubleshooting a less time-consuming, more effective undertaking.
1. Collect enough information to replicate the issue
If you can’t replicate an issue, you can’t fix it. Yet many help desk tickets come in with a description as vague as “I can’t login.” The result is an ongoing email exchange between the IT admin assigned to the ticket and the employee that reported the issue. This hunt for more information can go on for days. Those days cost money.
The issue at hand is often systemic behavior. The remedy is to ensure that enough information to replicate the issue is provided in the initial ticket. Some IT teams enforce acceptable reporting behavior by providing a “fix ticket” form that has a field that requires a submitter to list the steps to reproduce the given issue. In addition, many IT teams have simple programs in place to educate all parties about how to write an effective ticket and to monitor behavior moving forward to determine that the new, desired behavior is being adopted. Should the behavior persist, more direct, personal intervention is given. Regardless of remedy, just about all effective IT teams set a baseline expectation that requires submitters to provide adequate replication descriptions from the onset.
2. Customize your logs for actionable insight
Just as an incomplete help desk ticket prolongs time to resolution, logs that emit incomplete information also hinder troubleshooting efforts. Most logging frameworks provide options for customizing the format of log output. It’s important to make sure that all log formats provide a clear description of items and events being logged. In addition to date and time, the log entry should define the source emitting the entry (for example, MAC or IP address), along with a message field describing the intent of log entry. A data field that adheres to a structured format describing detailed information relevant to the item or event being logged is also useful. Learn more about log analysis for system troubleshooting.
3. Create useful error output at the source-code level
Consider the following error message sent to a log collector:
28 Nov 2017 15:49:08.871 err Bad number encountered
What does the error message tell you? Nothing more than that a bad number was encountered. You have no idea what the bad number is, why it’s an error, or how to address the issue. To remediate this, somebody is going to have to spend a lot of time just to uncover the source of the problem, and that expenditure doesn’t yet account for the time needed to fix it.
Now consider this error described in the log:
"numValue": 3727
"source": "at _.times (/home/apps/seventips/library/noodler.js:25:42)",
"message": "Bad number encountered. The submitted number, 9429 is an odd number. Odd numbers are not acceptable to the system. Please submit an even number",
"level": "err"
}
There’s a big difference. The error message above contains enough information to allow the IT admin to make an intelligent guess about the cause and source of the problem, and to begin troubleshooting.
A useful error message contains three pieces of information: a description of the error, the probable cause and, if possible, the most likely solution.
Ensuring that useful error messages are logged is about changing the behavior of an IT organization. It’s up to management to establish a compliance policy and then provide the procedures and tools necessary to support that policy. Thus, IT Admins will do well to define the format for useful error messages and then have a set of senior developers find or build a library of code that allows developers to easily create error messages that support the format. The adjustment should require a developer to add no more than a line or two of code to comply with policy.
4. Don't mistake symptoms for root cause
Making an issue go away is not the same as finding the root cause and fixing it. The trick for effective troubleshooting is to identify and report in detail on the root cause so that the problem does not crop up again. If you’re under a time crunch and can only make the symptom go away to meet a deadline, make sure you report that you have not identified the root cause and the fix is temporary.
5. Implement a comprehensive logging infrastructure and use correlation IDs
Making a call from a web page to a backend server is only one aspect of an application’s behavior in a distributed environment. That one call to the backend might in turn send data onto a message broker, a database, or another web-based API. Thus, the operational data is going to show up in logs well beyond the web server. When it comes to time to resolution, you’ll need a way to follow the aggregation and transformation of data throughout a request’s journey to all points in the transaction.
The easiest way to tie all calls together is to use and respect Correlation IDs. A Correlation ID is a unique identifier that gets passed with data between all points in a transaction. A Correlation ID allows the transaction to be traced in various logs. It’s a common technique generally supported by using the header attribute, X-Correlation-ID. (Figure 2)
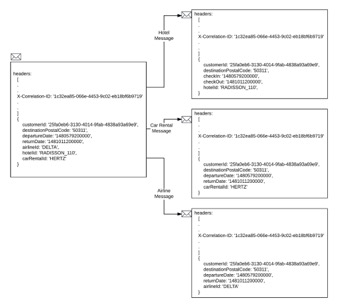
Using a Correlation ID will save you a lot of time troubleshooting between disparate systems.
6. Use system monitors and predictive analytics
These days, system monitors do a lot more than just collect data and store it. Modern system monitors have the intelligence to keep an eye on the system in which it is running. Also, a system monitor can aggregate all log information emanating from a machine into a single output. For example, InsightOps from Rapid7 will not only centralize all of your logging activity, it will also monitor CPU, memory, and disk usage on endpoints and send real-time alerts of known issues or critical events.
System monitors are essential for doing advanced troubleshooting, particularly for issues related to machine state over time. Also, using a predictive analysis tool to monitor dangerous trends in system activity will help you address smaller problems before they turn critical. The most effective troubleshooting to do is no troubleshooting at all!
Putting It All Together
In today’s modern IT environment, troubleshooting is unavoidable. It’s an important part of the revision process intrinsic to the principle of continuous improvement. Using the six best practices described above will make your troubleshooting efforts more effective and less costly. In fact, they might even make troubleshooting more enjoyable. And, as companies in the know understand, when work is enjoyable, quality is outstanding.




