
Java 8’s major changes- lexical closures, the stream API, e.t.c have overshadowed a slew of little gems, one of which I only discovered the other day- the @Contended annotation.
False Sharing
Chances are you’re reading this on a device with more than one CPU. There’s therefore also quite a good chance the you have more than one thread of execution running at the exact same time. There’s an equally good chance that some of your fancy multiprocessor CPU’s on-die memory (aka L2/3 cache) is shared between cores, like this:
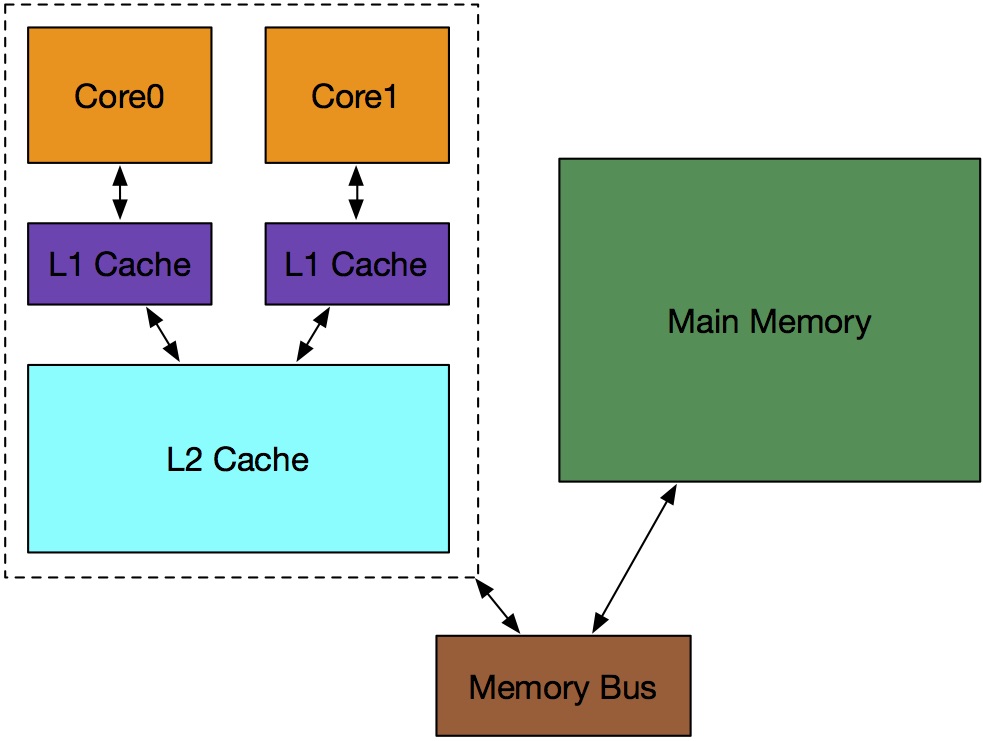
Independent cores play nicely when they’re sharing that L2 cache, right? Not quite, unfortunately. It turns out that x86-64 machines invalidate chunks of memory at the level of 64 byte-wide cache lines. On top of that, different cores can pull bits of data from main memory into the same cache line. We can formalise this with an example. Take a Java object like this:
public class SomeClass { public volatile long valueA; public volatile long valueB; }
Aside: on a mac you can get your CPU’s line size by running sysctl machdep.cpu.cache.linesize. On linux you use getconf: getconf LEVEL1_DCACHE_LINESIZE
Let’s say we’ve allocated one instance of SomeClass and two separate threads are reading/writing from the fields valueA and valueB.
We end up with a worst-case sequence of events that looks like this:
- After instantiation, our instance of SomeClass gets pulled into a cache line
- Thread 0 updates valueA
- Thread 1 updates valueB
- At this point, the cache subsystem knows each core has nonexclusive access to this cache line. To ensure coherence between CPUs, it’s marked as ‘dirty’
- Next time one of the threads attempts a read from the ‘dirty’ line, it has to reach out to main memory, introducing a big latency bump
Breaking this problem down, we start off with our SomeClass object. Getting some insight into how the JVM lays it out in memory will help us figure out what’s going on, so let’s run it through JOL:
OFFSET SIZE TYPE DESCRIPTION VALUE 0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1) 4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0) 8 4 (object header) 85 99 01 f8 (10000101 10011001 00000001 11111000) (-134112891) 12 4 (alignment/padding gap) N/A 16 8 long SomeObject.valueA 0 24 8 long SomeObject.valueB 0 Instance size: 32 bytes (reported by Instrumentation API) Space losses: 4 bytes internal + 0 bytes external = 4 bytes total
Using JOL could take up a couple of blog posts on its own, but suffice to say it’s an extremely handy tool for taking the guesswork out of JVM object sizes, internal structures, field layout and packing, e.t.c. Above, it’s telling us that SomeClass probably looks like this:
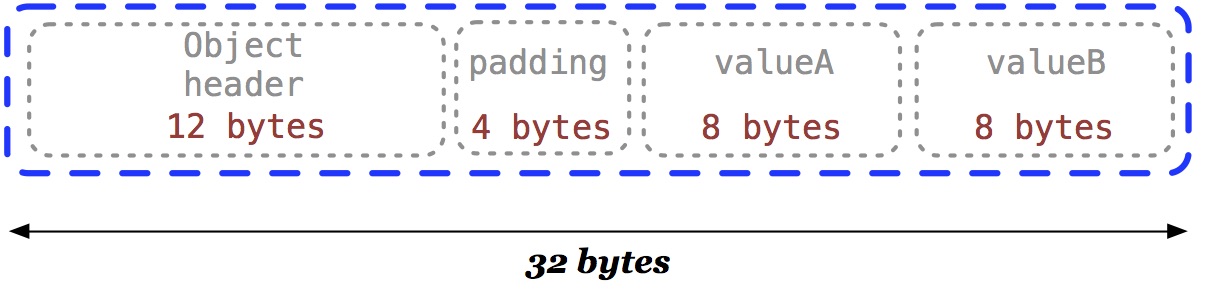
The object header is common to all JVM objects, regardless of language that generated the underlying class. It includes markers relating to the class type, lock status, metadata for garbage collectors, e.t.c. The root of our problem, though, is our two fields sitting next to each other: because SomeObject instances comfortably fit in a cache line (they’re half the size of one line on x86-64 architectures), valueA and valueB can exhibit false-sharing when different threads are independently updating them. Let’s walk through that; step 1 in the above sequence leaves us in this state:

Next, CPU0 updates valueA:
When CPU1 updates valueB, the line gets marked as ‘dirty’:
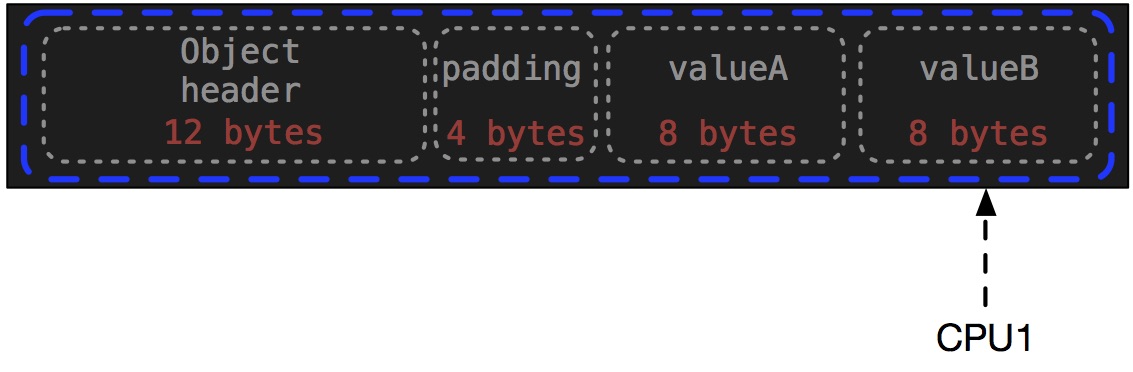
Since the cache subsystem has flagged this whole line as dirty, when CPU0 next does a read of valueA it must reach out to main memory to repopulate it- a huge (and often silent) performance killer!
How do we fix this? The most obvious way is to ensure independent fields that are heavily contended by different threads aren’t crowded into the same cache line.
Enter @Contended
Prior to Java 8, programmers concerned with cache-contention at critical points in their code had to resort to tricks like this:
public class PaddedObject { public volatile long actualValue; public volatile long p0, p1, p2, p3, p4, p5, p6, p7; }
This has the effect of adding 56 bytes-worth of empty space on top of the 8-byte long value we care about. While that did the job, changes to javac in Java 7 optimized more zealously for space-efficiency, removing the unused fields. It also played havoc with some style-checkers and just generally looked a bit strange. It’s also platform dependent (although based on this mail thread, it seems that’s not easily solved).
Java 8 quietly introduced another way of achieving field padding by way of JEP 142 and the @Contended annotation which lets us do away with declaring dead variables and instead instructs the JVM to add 128 bytes worth of space before and after the ‘hot’ field:
public class PaddedObject { @Contended public volatile long valueA; public volatile long valueB; }
Let’s have a look at our padded object through JOL:
OFFSET SIZE TYPE DESCRIPTION VALUE 0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1) 4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0) 8 4 (object header) 85 99 01 f8 (10000101 10011001 00000001 11111000) (-134112891) 12 4 (alignment/padding gap) N/A 16 8 long PaddedObject.valueB 0 24 128 (alignment/padding gap) N/A 152 8 long PaddedObject.valueA 0 160 128 (loss due to the next object alignment) Instance size: 288 bytes (reported by Instrumentation API) Space losses: 132 bytes internal + 128 bytes external = 260 bytes total
Contrast that with SomeClass- the JVM has intentionally introduced a large amount of padding (twice the size of our cache line) to avoid any false-sharing between valueA and valueB. This means it’s extremely unlikely that a stray adjacent field will end up in the same line as valueA.
Does any of this have an effect on performance? Let’s do a quick benchmark of the padded and unpadded versions of SomeClass, where there is a separate thread updating each variable. I created a simple benchmark with two threads, one updating each value. You can see the whole implementation and details of how to run it on GitHub here. The results are stark though:
Updating unpadded version 1B times Took: 55.57987619sec Updating @Contended version 1B times Took: 7.041363315sec
It’s obvious that eliminating false-sharing can have a huge effect on throughput of performance-sensitive parts of a system. This isn’t a purely academic concern, either: common constructs like counters and queues often fall victim to it in multithreaded environments.
It probably goes without saying that you definitely shouldn’t be sprinkling @Contended regularly around your application code- optimizing field layout is an NP-hard problem and continuously second-guessing the JVM is almost certainly going to give you slower, more delicate and unreadable code. If you need field padding, you probably know about @Contended already! That said, with tools like LMAX’s Disruptor and Java’s LongAdders as well as the explosion of JVM-hosted languages emphasizing their concurrency support, it’s becoming incumbent on developers to have at least a passing awareness of phenomena like false-sharing.
Logentries supports log4j/2 and Logback making capturing logs from your Java applications seamless.
Creating a Logentries account is free and takes less than a minute. Sign up here!




