

Engineers in fast moving, medium to large scale infrastructures in the cloud are often faced with the challenge of bringing up systems in a repeatable, fast and scalable way. There are currently tools which aid engineers in accomplishing this task e.g. Convection, Terraform, Saltstack, Chef, Ansible, Docker. Once the system is brought up there is a maintenance challenge of continually deploying and destroying the resources. What if we can hash the inputs for describing an infrastructure, where the final hash acts as an entry point into the defined infrastructure? What if the input model was agnostic of underlying tools?
At a recent SREcon2016Europe event I gave a lightning talk to put the idea of hashing infrastructures out there, however, 5 minutes to give a talk about the idea was too short, the topic was too theoretical and hard to grok in 5 minutes.
Background
We like to treat infrastructure as code, however by treating infrastructure as code it means that we need to test and validate that the output is what we would expect. Is the output from this code really reproducible and immutable? Being able to repeat a process of constructing infrastructure does not mean that the system is reproducible, at least not with a high degree of confidence.
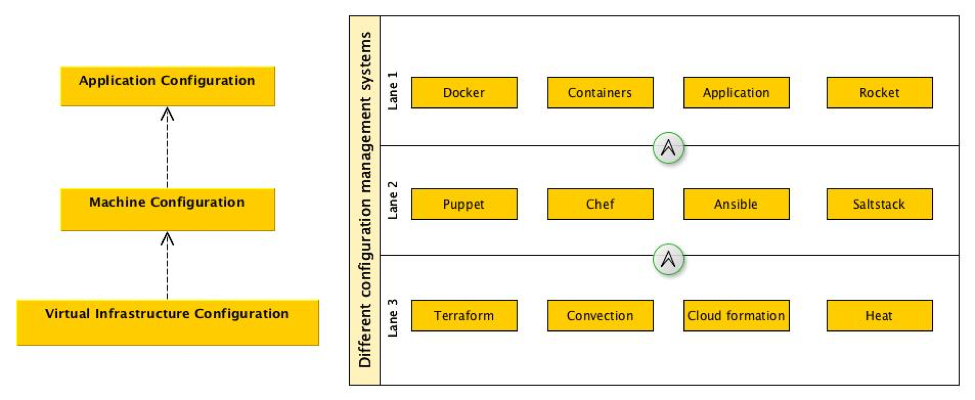
There are already existing tools which address the repeatable and reproducibility of infrastructure at different tiers. For example, tools like Terraform and Convention allow engineers to manage the clould infrastructure. Configuration management tools such as Ansible, Saltstack, Chef, NixOps and Puppet provide a means of laying down what a server might look like right up to the point of deploying the application. Container formats such as Docker, Rocket and plain LXC allow developers to package up applications to be deployed on the provisioned machines. At each of these tiers of configuration management, it’s possible to make some associations and relationships between a load balancer to a group of hosts which provide a particular service. As a SRE, Platform Delivery, DevOps, or operations ninja that attacks the problem of maintaining all these components we place these definitions into version control. Most engineers in this space are aware of modern distributed version control systems such as Git and Mercurial so there is a notion of hashing content already. It’s clear that some tiers are better serviced at being reproducible, but it’s not immediately obvious what the system looks like when taking a broader view of how everything is interconnected.
Why would one want to do this?
If the process of recreating a system is already repeatable with a combination of tools and configurations then why do we want to hash the configurations? At first, it is simply to be able to validate the reproducibility of the infrastructure. Questions such as how are scaling groups and load balancers related to a group of hosts, how are different services related, what is the shape of the network and the security groups that are in place, how are all these things interconnected? By having this output that can be validated as reproducible, it may be possible to track behavior and changes over time.
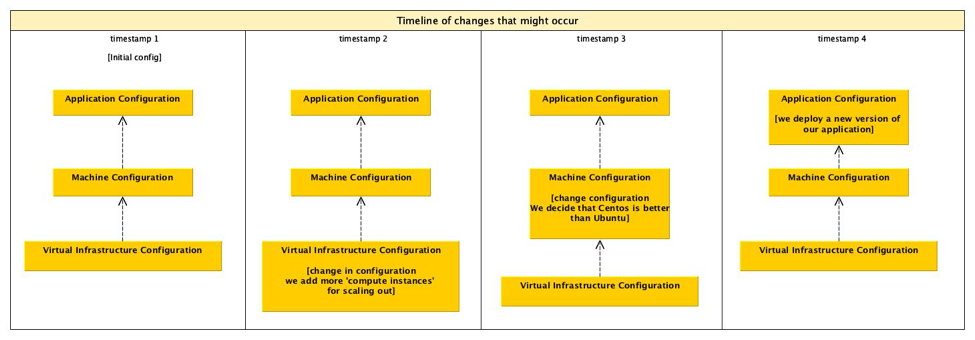
Another interesting application of hashing the infrastructure is that the hash could be used as an entry point into an infrastructure. If the hash was used to label (for example, a load balancer), then as time progresses and changes happen, a new hash is generated, a new entry point is created to the new infrastructure. This would lead to interesting new deployment models where minor changes in the relationships between the components would lead to a new hash and infrastructure being generated. This would assume that infrastructure is cheap and it’s ok to replicate parts of your infrastructure.
How would one approach this?
Firstly, the idea of hashing configurations is not a new idea, the concept has been around for a number of years. Notably systems such as Nixpkgs and Hashstack have been applying this idea for a while now. It would appear to be a natural step to take configuration input for infrastructures and hash them.
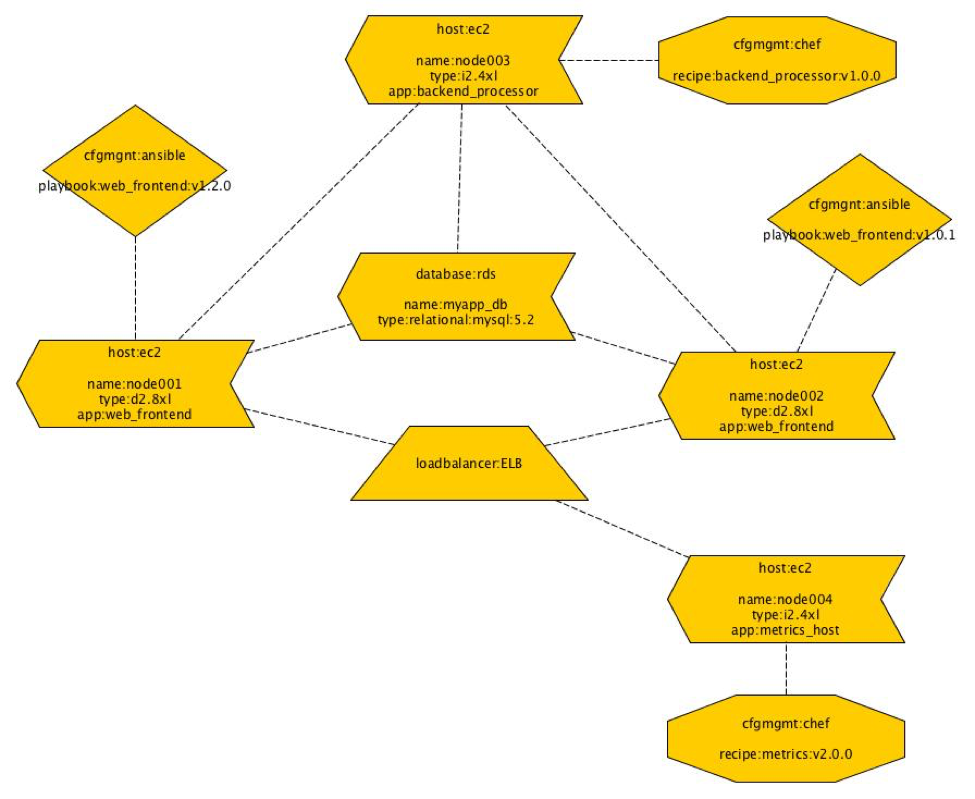
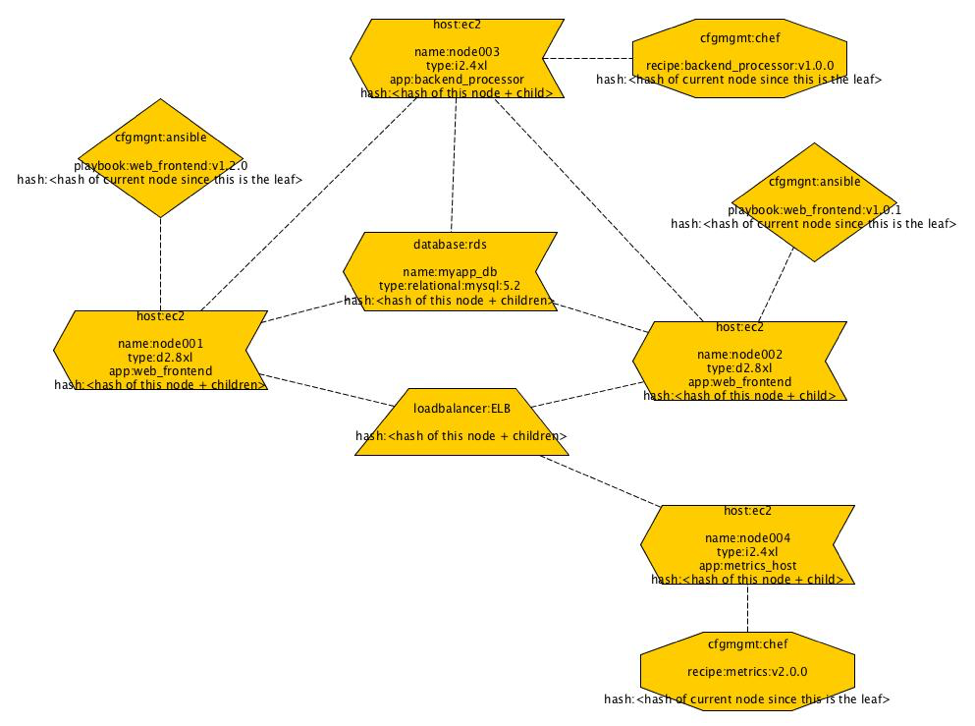
How and what is hashed can be approached in a number of different ways. One could model the system in an existing DSL (domain-specific language). If no DSL exists then create yet another DSL to describe this. Alternatively, extract information from existing tools such as Terraform, Convention, Ansible, Saltstack etc.. These tools already track internally what they think things should look like and how things are related and connected. If we could take all of this information from these tools or model the infrastructure as a whole with a DSL then we could generate a graph of all the components. Each node in the graph should ideally contain the relevant information for making it unique. However, after having a discussion with Mark Suter at SREcon2016Europe, it may be a better idea to have all the information and brute force the problem by hashing everything and just building a Merkle tree. Once the graph is generated the hashes should be generated for each node from the edges first. At the end of the process when the final hash is generated, it should be used to address the infrastructure and it should be recorded. One example of this might be to use it as a label for a load balancer or an IP address. With the hash, it should be possible to give it a more human friendly label that could be tagged and version controlled much like how Git treats HEAD which points to the latest commit in a repository. Once all this is generated the graph could be used to really generate the infrastructure. If changes are made to the system, then the process described previously is repeated to generate a new hash. The new hash would be used to label the new infrastructure with the new changes. Depending on how the graph has changed there may be components which have not changed which would lead to shared components between the old and new infrastructure. This would lead to interesting and new descriptions of infrastructures and probably new deployment methods to allow for easy rollbacks from bad changes.
Final thoughts
During the SREcon2016Europe lightning talks, I got a few questions and comments as I threw this idea out to the general community, it’s currently not well thought out and very few people appear to be taking this particular angle of differentiating repeatable processes from reproducible systems. As a sweeping statement and comment on where this space is headed, perhaps we should not think about infrastructure as code, but rather infrastructure as configuration. If we can decouple the configuration of the infrastructure from the tooling that generates the infrastructure it would be easier to grok the idea of hashing infrastructures.





